
We are excited to announce some of the new features and our biggest update to date. These features have been suggest by our users, for our users!
By Admin @November, 23 2021

Updates from the WebAutomation.io team about improvements, fixes, new features and more.
We love to hear from you!
We firmly believe that customer is the king and we believe in growing along with our customers and their needs. As you know we have already built features based on customers requests. Email us your thoughts anytime at info@webautomation.io
We are excited to announce some of the new features and our biggest update to date.
Our Concierge Web Scraper service allows you to collaborate with one of our experts to build you a custom web scraper that you can run on Webautomation. Although we offer to do this for free for your first extractor, customers who wish to build more than one can now pay a small fee for this service as an add-on. You can order your custom made extractor here.
Our pre-defined extractors, by default, set the name to the domain name. For example, goolge.com.
Customers that want to rename the web scraper to something a bit more meaningful to the function or the use of the PDE can do that now. Just click on the pencil symbol next to the default extractor name, rename and save.
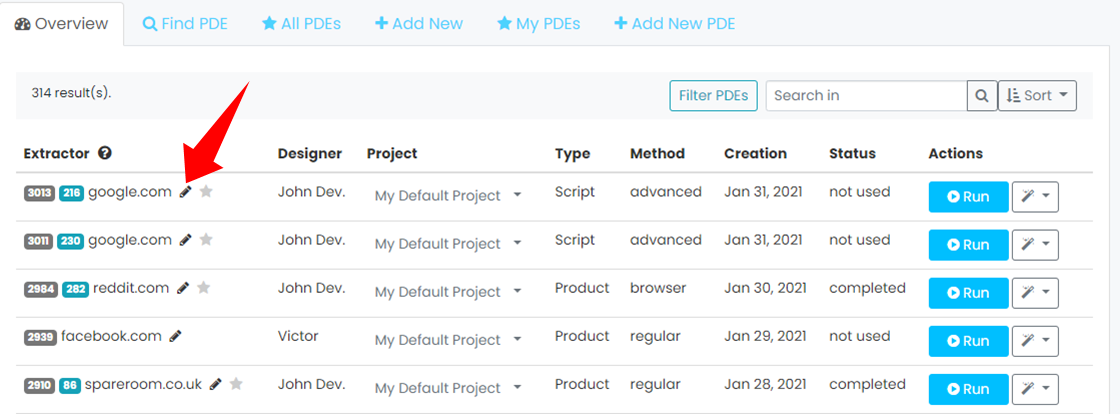
In order to speed up a current web scraper run, customers can now increase the concurrency of an extractor. Concurrency means each crawl is simultaneously running on our cloud servers. In the settings of an extractor, you can edit this number to increase the concurrency. Please note there are limits for this feature depending on price plans.
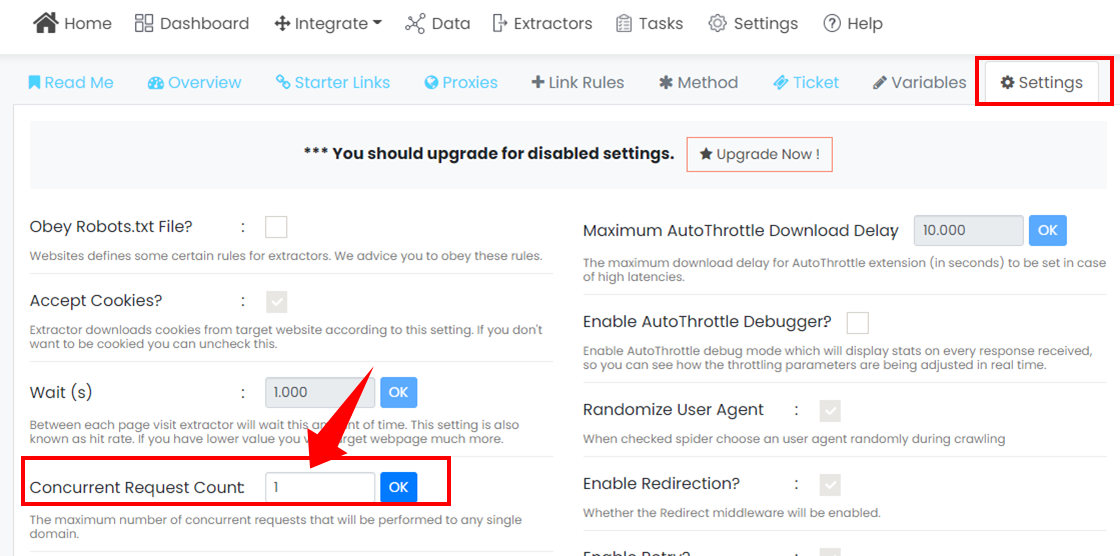
We have added help icons next to important features inside the app. This will help users quickly understand what the feature means, what it can do and hence can be used for without being redirected out of the app.

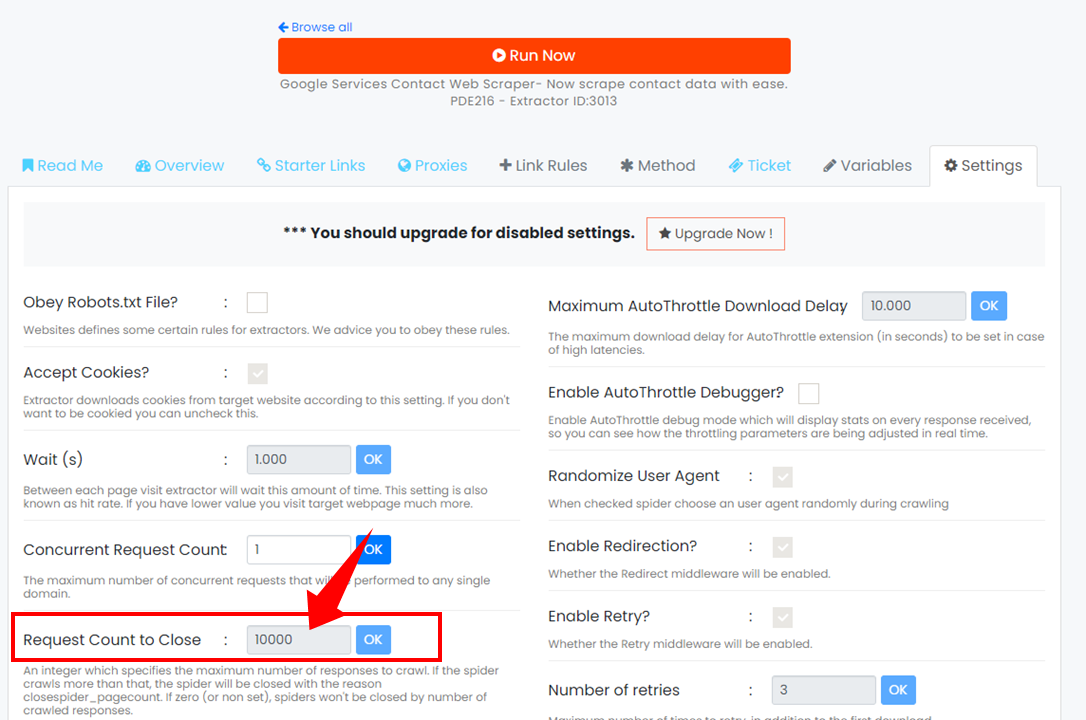
Whenever a web scraper is used, it crawls through every page within the website based on the search URL provided. Sometimes, this could be thousands of pages, depending on the website you visited. To give you more meaningful results for better insights, we added this feature that doesn't let the web scraper stop, just after working on a few rows. This ensures you get the best data possible every time you scrape.
Please note this feature has limits and restrictions based on your plan
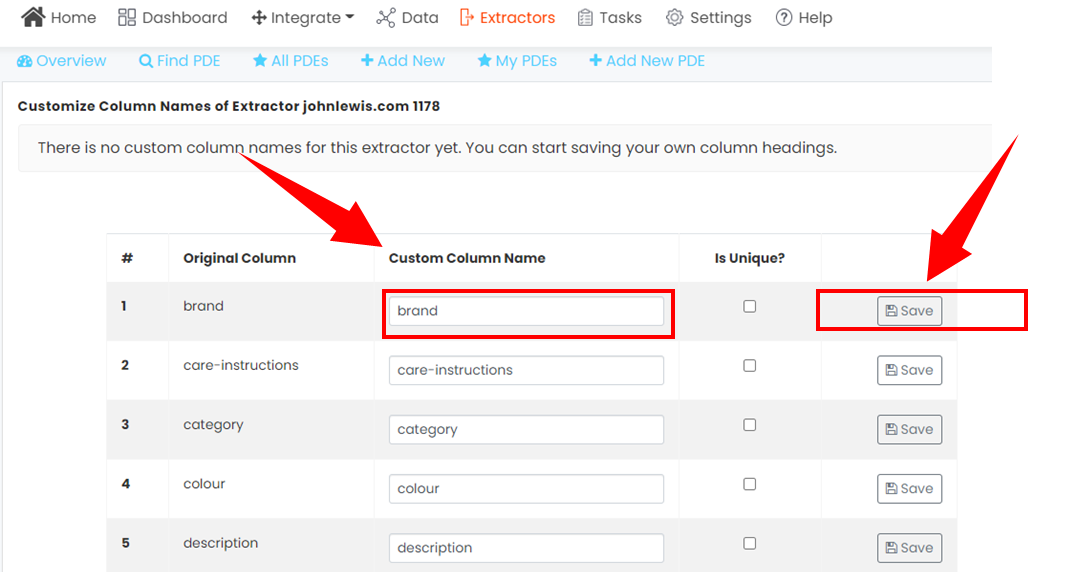
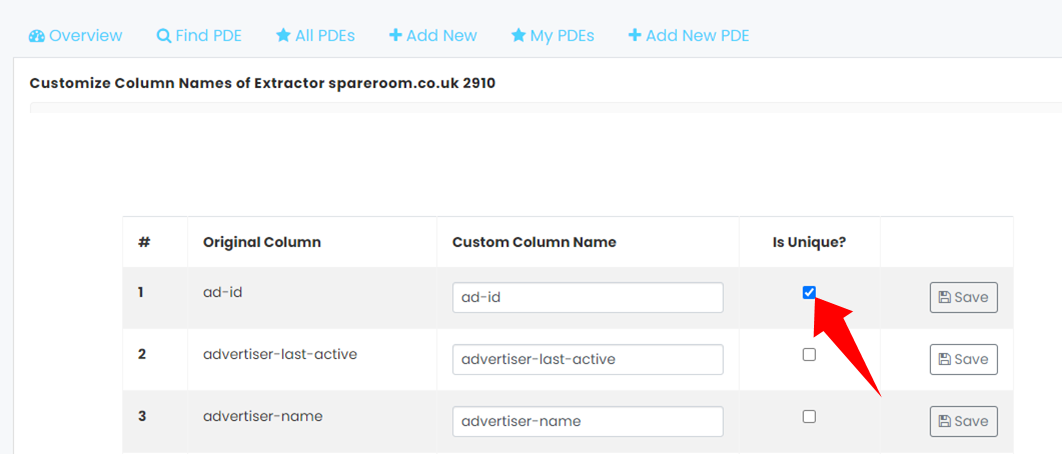
With our pre-defined web scrapers, all the columns and the names are pre-set by default. Usually named after the same title as of the webpage. Sometimes, some users want to change the names of the column headers to something more meaningful or drop some columns which might not be useful to them.
This guide helps you achieve that.- See Full Feature Guide
This unique feature ensures that all values in a column are different. Users can use this feature to set a primary key, making sure that values stored in a column or a group of columns are unique across rows in a table, thus avoiding any duplicate data.
This can be very helpful when you want to ensure that values stored in a column or a group of columns are unique across the whole table such as email addresses or usernames.
Our predefined web scrapers are designed specially to help you gather all the data you need, with just a click of a button, without having to write any code!
And the best part? Our web scrapers are easy to use and FREE to try!
We released 41 new PDE's in January
Here are some of the most popular ones:
Reddit Web Scraper for WallStreetBets Subreddit
Yahoo Finance Cryptocurrency Web Scraper
Very Web Scraper- Now extract e-commerce data with ease
Yellow Pages Web Scraper- Now extract business data with ease.
Idealista Property Listings Scraper
Indiamart Product Supplier Data Extractor
Alibaba Product & Price Web Scraper
Amazon seller information web scraper- Now extract seller information with ease
Pistonheads used cars Web Scraper
That’s all for now. Follow us on Twitter for the latest updates!





 Linkedin
Linkedin