
The Data output from web scraping isnt always clean and ready to be used. In this tutorial we will show you out tips and tricks using Python
By Admin @August, 17 2022

CLEANING OF SCRAPED HTML DATA
Web scraping is an automated method used to extract large amounts of data from websites. The data scraping usually is unstructured. So, cleaning this scraped data is necessary to convert the unstructured data into structured form. From another perspective, spending time cleaning up messy data can fill the large gaps that your processor will experience when waiting for it to be downloaded from its host.
This section covers several useful clean-up operations of scraped data of CSV files using Python programming
When you get data from a website or from an HTML code. Then you may need to remove tags from the scraped data. Here are the steps you need to follow to do it using python.
Python provides various libraries to perform different operations. The BeautifulSoup library is used generally to deal with HTML pages in python. The beautifulSoup library for versions after python 3 is renamed as beautifulsoup4. Usually the web scrapped data will be placed in an excel sheet or CSV files. To handle those CSV files using python programming a library names pandas are being provided.
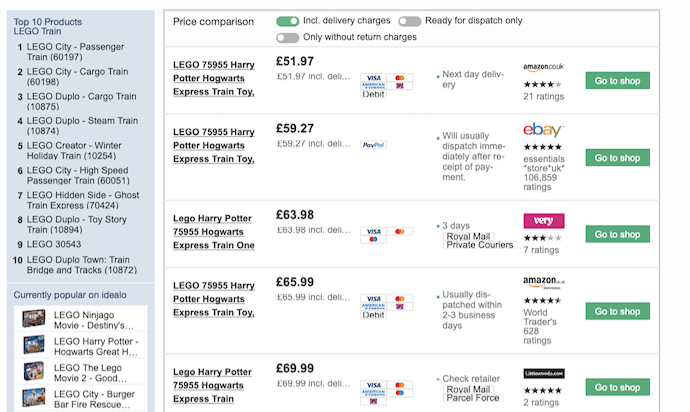
In this article, we provided a solution to remove HTML tags without using BeautifulSoup. Let us see what to do to remove the HTML tags from the scraped data. Let us consider sample data as follows which is saved in . CSV format:
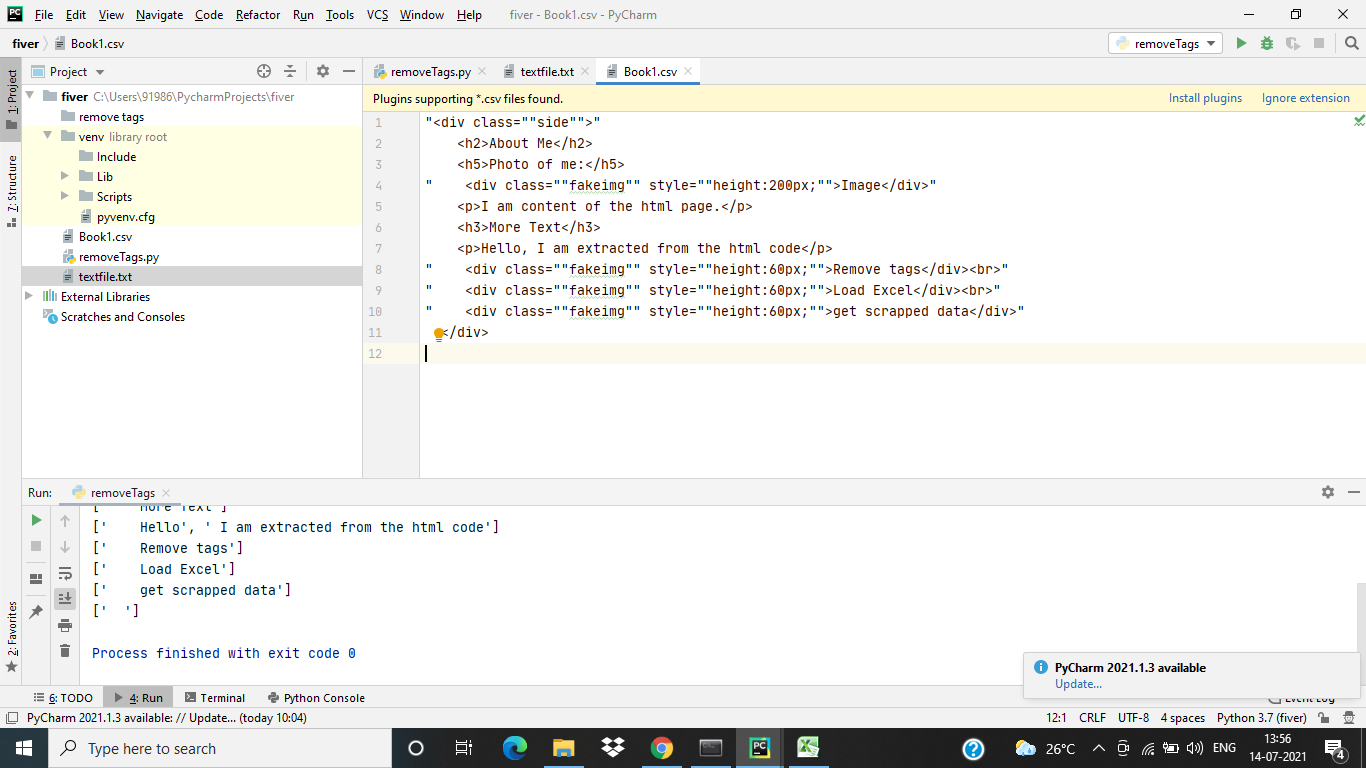
If you have data similar to the above figure shown and you are willing to remove those HTML tags and get the data. The following code helps you out.
import re import csv #Open and Read the content of the CSV file f=open("Book1.csv",'r') csv_f = csv.reader(f) f1=open("textfile.txt",'w') #Identify all the regular expression such as <*> and substitute with empty space. def cleanhtml(raw_html): cleanr = re.compile('<.*?>') cleantext = re.sub(cleanr, '', raw_html) #Write data into text file f1.write(str(cleantext)) f1.write("\n") print(cleantext) for row in csv_f: cleanhtml(str(row)) f.close() f1.close()
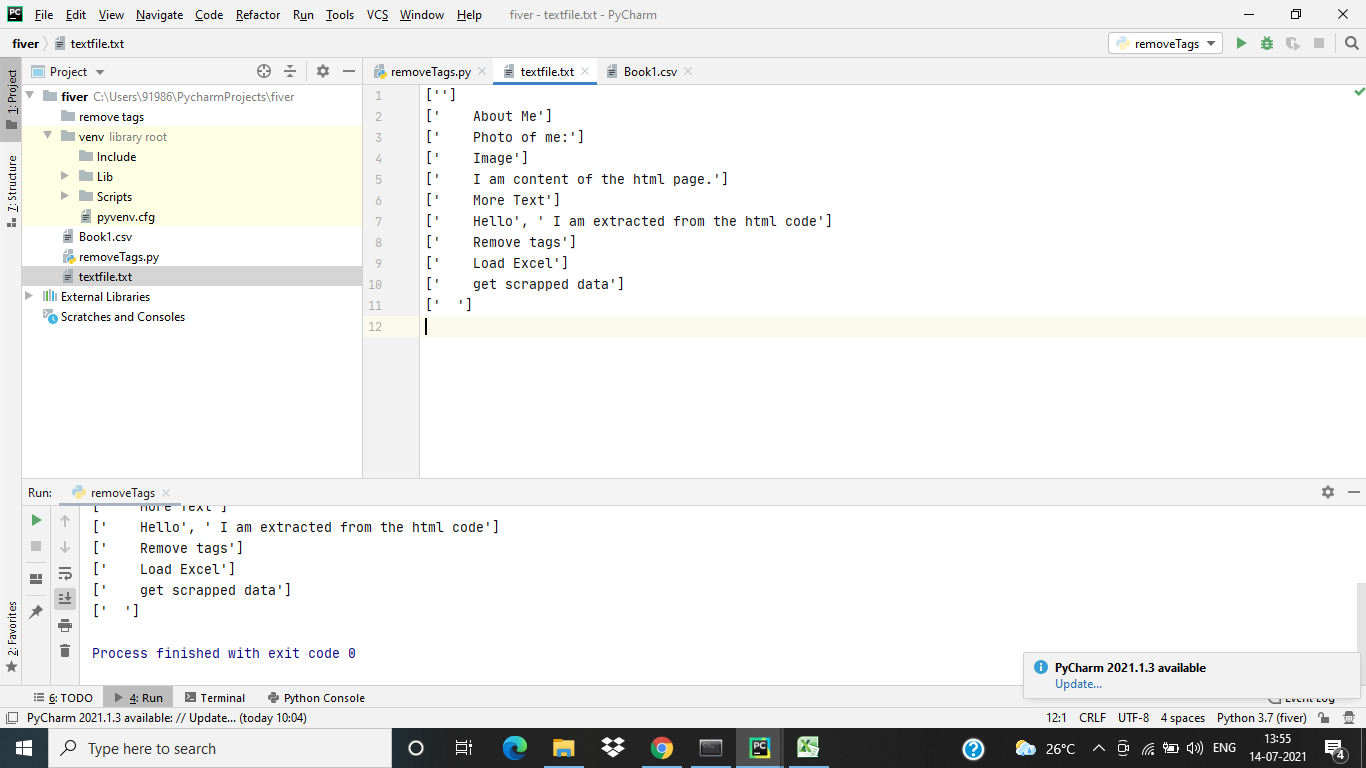
After removing the tags the output text file will be as follows:
When you get data into any spreadsheet from a website. You are likely to get extra spaces along with important data. There can be leading and trailing spaces, several blanks between words, and thousand separators for numbers.
Replace() function along with regular expression is used to strip the trailing and leading spaces present in the data.
Let the CSV file have the following data.
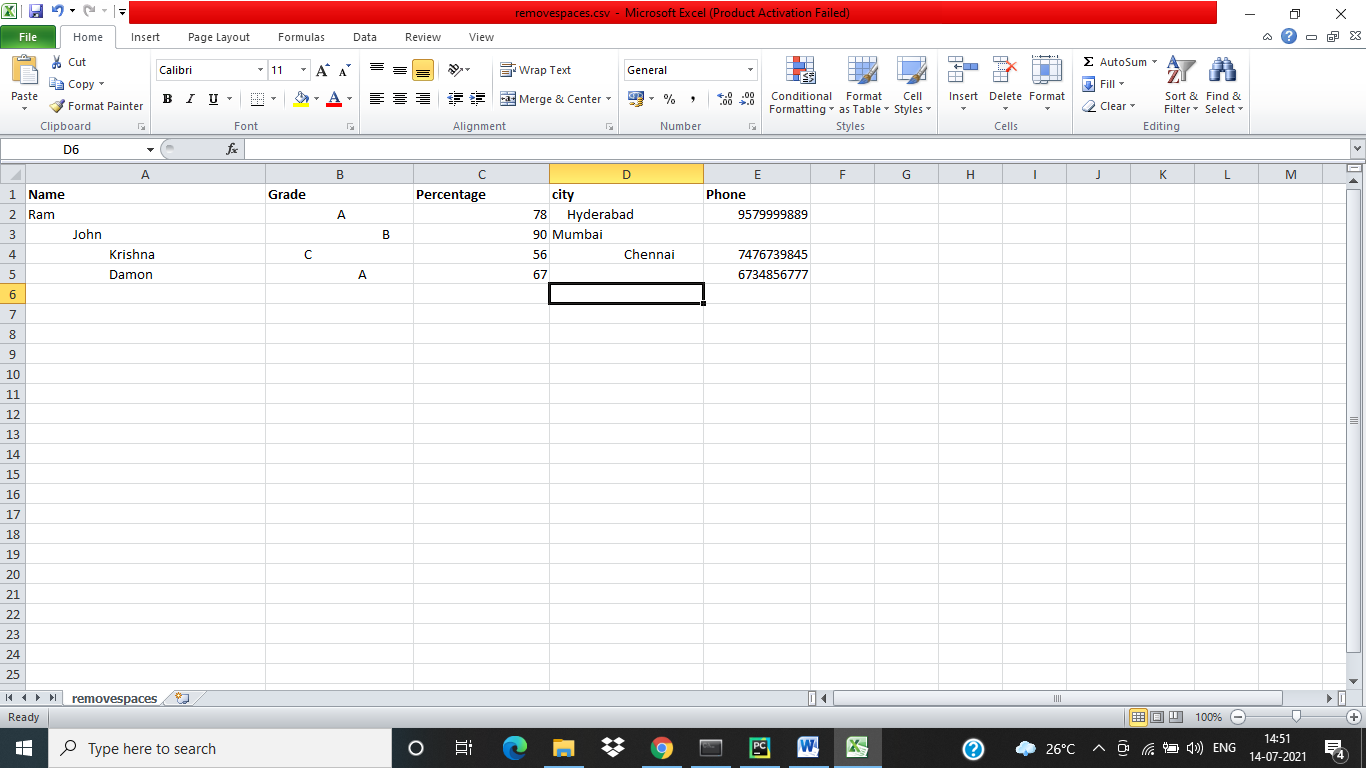
The following python code is used to remove spaces.
import numpy as np import pandas as pd import re #Load the content of CSV file into python code def read_csv_regex(data, date_columns=[]): df = pd.read_csv(data, quotechar='"', parse_dates=date_columns) # remove front and ending blank spaces df = df.replace({"^\s*|\s*$": ""}, regex=True) # if there remained only empty string "", change to Nan df = df.replace({"": np.nan}) print(df) df.to_csv("removedSpaces.csv") return df columns=["Name","Grade","Percentage","city"] read_csv_regex("removespaces.csv",columns)
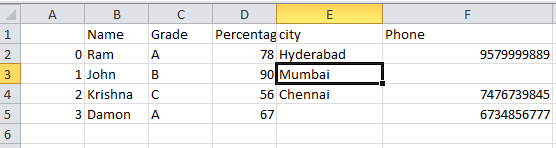
The CSV sheet after removing the trailing and leading spaces will be as follows.
Numbers that are stored as text can cause unexpected results. So to convert the numbers that are stored in text format (as String) python provides a function to_numeric(). This function is used to convert the values of columns with numerical text to numerical values.
Let the sample spreadsheet with columns consisting of numerical values in text format be as follows.
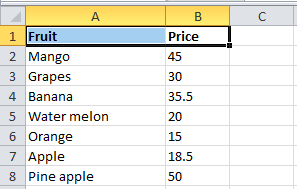
The python code to load this CSV file into the python file and convert the numbers in text format to numerical type and store the new sheet is as below.
import pandas as pd #load the CSV file into python code df = pd.read_csv(r"Numbertype.csv") print(df.dtypes) #convert to numerical value df['Price'] = pd.to_numeric(df['Price']) #write the converted data into CSV file df.to_csv("NumbertypeConvert.csv")
The resulting CSV file with updated data along with updated data type will be as shown.
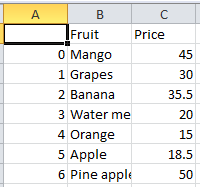
If you would like to change yes to TRUE and no to FALSE for the data present in the sheet then the “map()” function can be used. The same is applicable if you want to change Boolean TRUE or FALSE into 1 or 0.
Let us consider same data as follows:
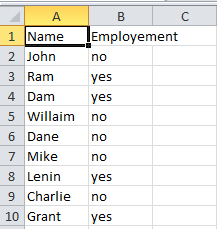
The python code to convert the yes/no to Boolean expression is:

df=pd.read_csv(r"filepath\filename.csv")
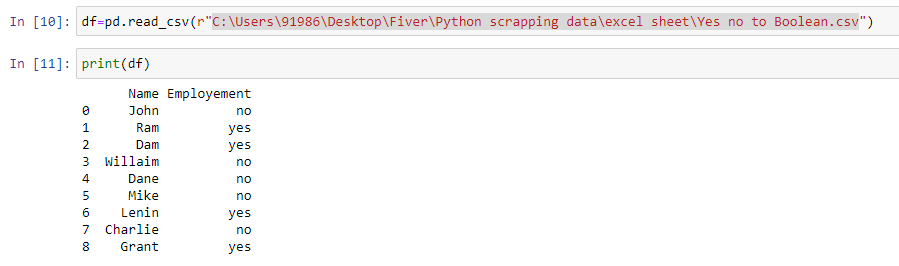
“df['Employement'] = df['Employement'].map({'yes':True ,'no':False})

df.to_csv("yesnoconverted.csv")
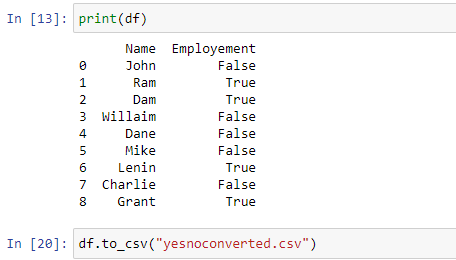
The updated CSV content will be as follows
For converting date details present in the sheet into machine understandable format python library “pandas” provides a function “to_datetime()”. This function is used to convert the date present in the column into machine-readable format.
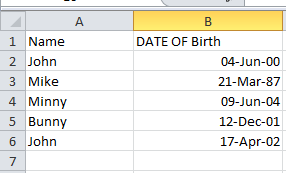
To implement the date conversion, let us consider a sample spreadsheet with the Name and Date of Birth as follows:
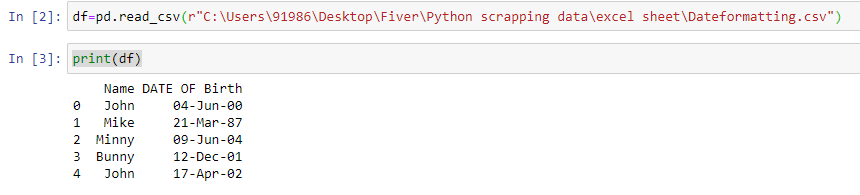
The step-by-step python code to convert the date into machine-readable format is as follows:


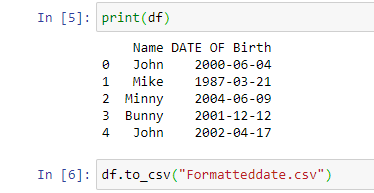
The final CSV file will be as follows:
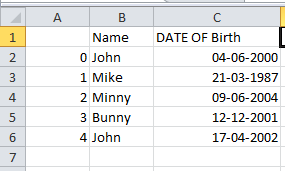
Removing a few columns from the sheet
When dealing with spreadsheets if you want to delete any of the columns temporarily then drop() function of data frames helps out.
Let us consider a CSV file with four columns and you need only the first and last column to use.
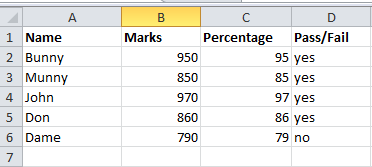
The following code helps out
import pandas as pd df=pd.read_csv(r'C:\Users\91986\Desktop\Fiver\Python scrapping data\excel sheet\removingcolumn.csv') to_drop=['Marks', 'Percentage'] df.drop(to_drop, inplace=True, axis=1) print(df)
The resulting sheet has only two columns

When you are using a sheet that consist of data, if there are any empty cells and you are trying to ready empty content and perform computations it would lead to errors. So it is necessary to remove empty cells present, they should be removed.
Let us consider an example CSV file with the following data
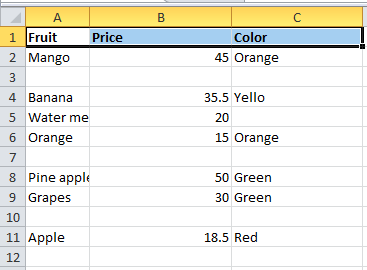
The dropna() function helps to remove empty cells present if any in between the data.
The following python code helps in removing the empty cells:

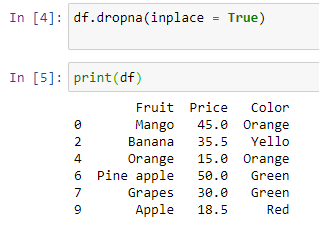

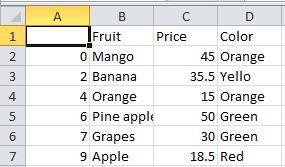
The emptycellsremoved.csv file data will be as follows
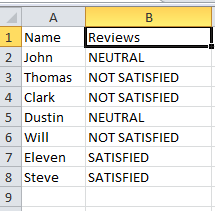
The reviews given in text format can be converted into numbered format reviews using map() function similar to converting yes/no to Boolean conversion.
Let the sample CSV file by:
The following python code is used to change text reviews into numbered reviews.

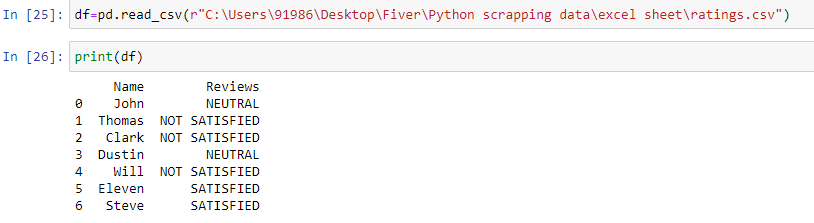
“df['Reviews'] = df['Reviews'].map(
{'NEUTRAL':2 ,'NOT SATISFIED':1,'SATISFIED':3})”

“df.to_csv("numberreviews.csv")”
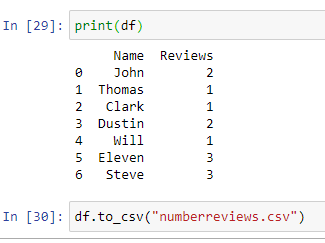
The resulting numberreviews.csv content will be as follows
Python provides a function to remove duplicate entries if any are present in the sheet that you are using.
drop_duplicates() function is useful in identifying the duplicate entries and removing them based on the condition mentioned inside the brackets.
“data.drop_duplicates(keep=False,inplace=True)” – is used to remove the duplicates if all the columns have the same data matching with another row.
“data.drop_duplicates(subset ="Attribute/column name",keep = False, inplace = True)” – is used to remove duplicates by considering only the columns mentioned in the subset field.
Let us consider a dataset with the following data:
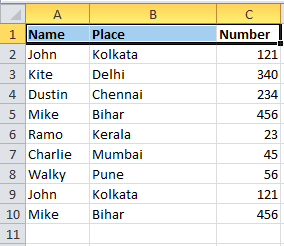
The following python code helps in removing duplicates.
“import pandas as pd”
“df=pd.read_csv(r’filepath\filename.CSV)”
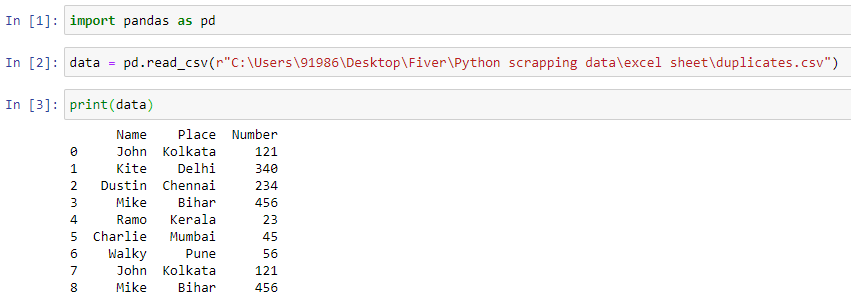
“data.drop_duplicates(keep=False,inplace=True)”
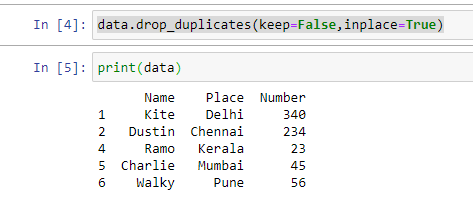
“data.to_csv("removedduplicates.csv")”

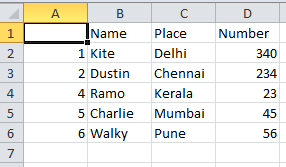
The removedduplicates.csv file will be as shown below
There are inbuilt functions available in python to change the case of the text as per the requirement. The functions available are:
Series.str.lower()- To convert all the entries of a column to lowercase
Series.str.upper()-To convert all the entries of a column to upper case
Series.str.title() - To convert the first letter to upper case and all the other letters to lowercase for all the entries of a column mentioned.
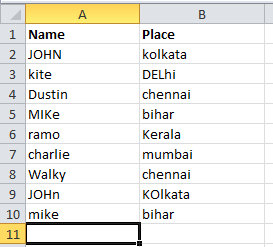
Let us take an example . CSV spreadsheet.
Python programming involves the following steps
“import pandas as pd”
“df=pd.read_csv(r’filepath\filename.csv’)”
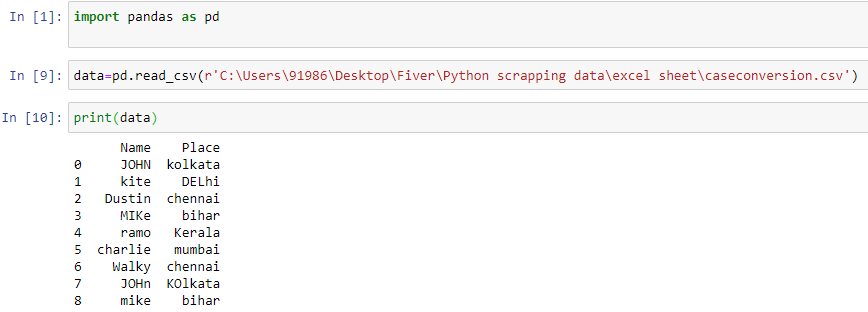
data["Place"]= data["Place"].str.lower()
data["Name"]=data["Name"].str.lower()
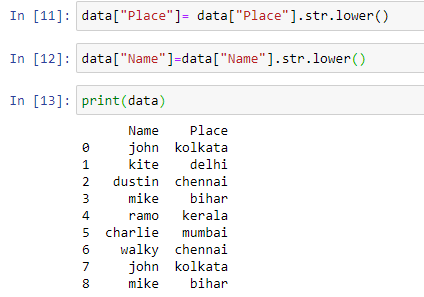
data["Place"]= data["Place"].str.upper()
data["Name"]=data["Name"].str.upper()
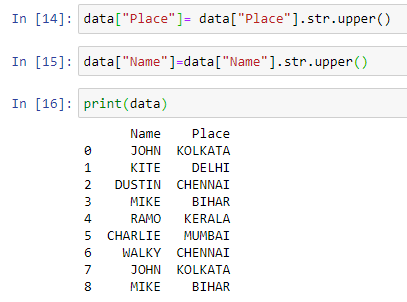
data["Place"]= data["Place"].str.title()
data["Name"]=data["Name"].str.title()
The Unix timestamp tracks time as a running count of seconds. The count begins at the "Unix Epoch" on January 1st, 1970, so a Unix timestamp is simply the total seconds between any given date and the Unix Epoch. Since a day contains 86400 seconds (24 hours x 60 minutes x 60 seconds), conversion to Excel time can be done by dividing days by 86400 and adding the date value for January 1st, 1970.
Apart from these calculations python provides a function to_datetime() to directly convert the Unix date into actual date time format.
Let us consider certain Unix time values to verify the above-mentioned function
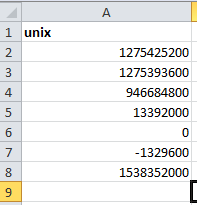
The python code to convert the Unix date data present in the CSV spreadsheet into normal date time format requires:
“import pandas as pd”
“df=pd.read_csv(r’filepath\filename.csv’)”
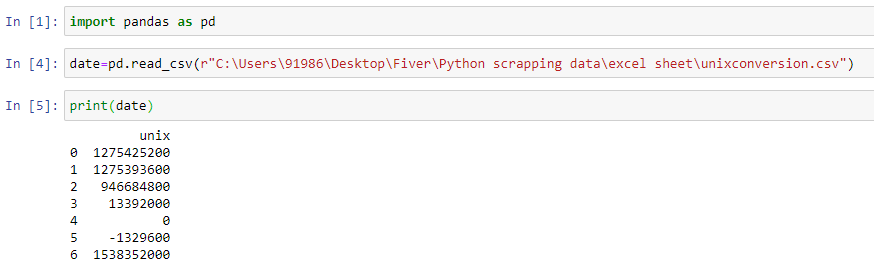
date['datetime'] = pd.to_datetime(date['unix'], unit='s')
The best approach to web scraping is with the use of already made scrapers like the Google maps scraper and Zillow homes extractor. The pros of using such ready-made web scrapers are that they make the work a lot easier and faster than the alternative.
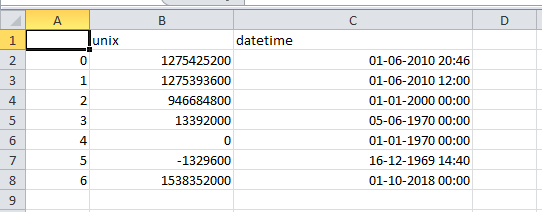
The final converted time sheet will be as shown below
When data is scrapped from a webpage it will be in the form of paragraphs sometimes. Then there will be a need to split the text into different columns based on the requirement. The data can be split in python using a general str.split() function which is used to split the content based on the character mentioned inside the split function.
Usually there will be a requirement to split based on the space “ “ . Let us see an example where data from one column is spitted and placed in more than one column.
The sample sheet data is as follows:
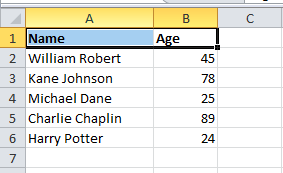
Following are the steps to be followed
“import pandas as pd”
“df=pd.read_csv(r’filepath\filename.csv’)”
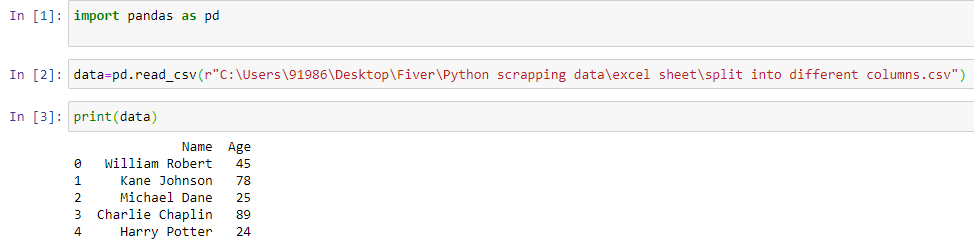
data[['First','Last']] = data.Name.apply(
lambda x: pd.Series(str(x).split(" ")))

data.to_csv("splitteddata.csv")
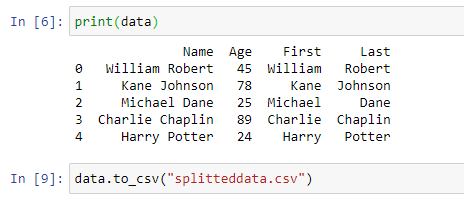
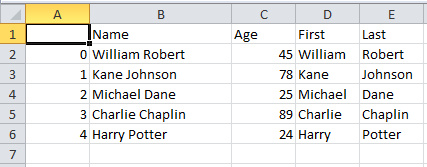
The final sheet with the first name and last name as separate columns is as follows
While working with sheets and web scraped data, you may need to change the currency symbol or sometimes remove the currency symbol in the column to make the computations easier.
The replace() function of python helps in changing currencies or even removing currency symbols.
Let us take the sample sheet as shown
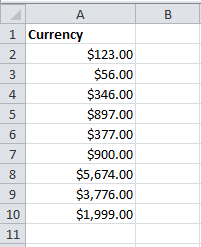
The following python code helps out in converting currency
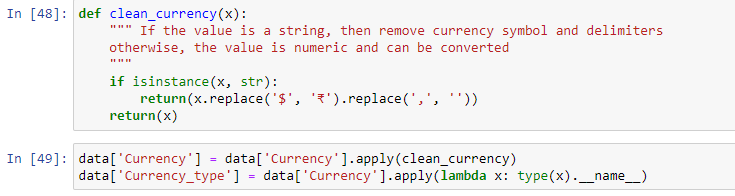
We aim to make the process of extracting web data quick and efficient so you can focus your resources on what's truly important, using the data to achieve your business goals. In our marketplace, you can choose from hundreds of pre-defined extractors (PDEs) for the world's biggest websites. These pre-built data extractors turn almost any website into a spreadsheet or API with just a few clicks. The best part? We build and maintain them for you so the data is always in a structured form. .
Related Blog Post
How to Clean Web Scraped data using excel/google sheets
RECENT POSTS
RELATED POSTS
CATEGORIES
follow us on



 Linkedin
Linkedin