
By Admin @July, 1 2021

We are excited to share some powerful new features we've added to WebAutomation this month.
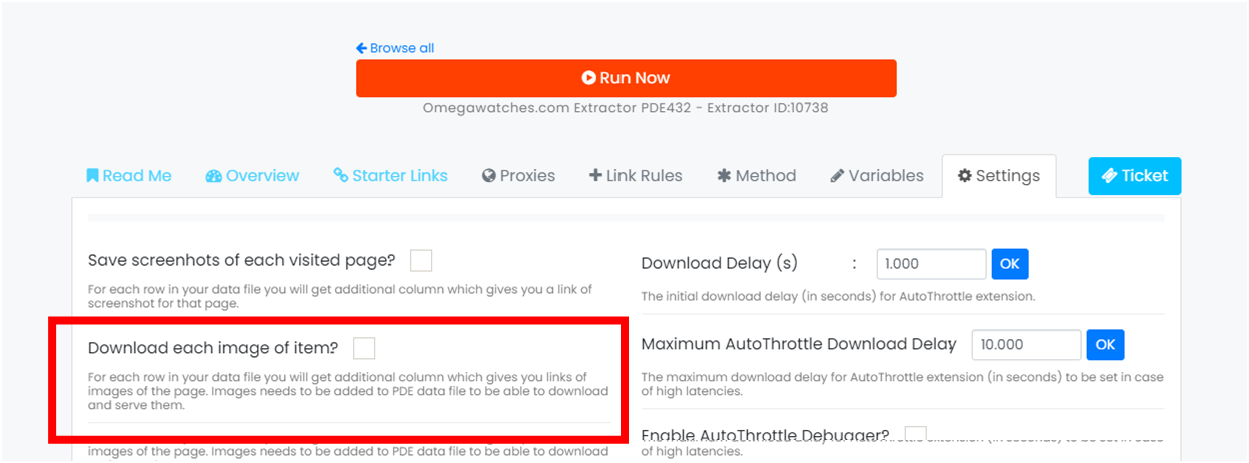
Our new feature allows you to capture a full-page screenshot of each page you are scraping.
Why take a screenshot?
It is a common practice in web scraping to capture a screenshot of a website either for testing purposes or as proof to verify the data being extracted is exactly what is displayed on the website.
With this new capability, you can now capture these screenshots automatically with WebAutomation.
See this article for full feature details and how to use it.
With our new feature, you can save a copy of images on Webautomation's cloud and then download them.
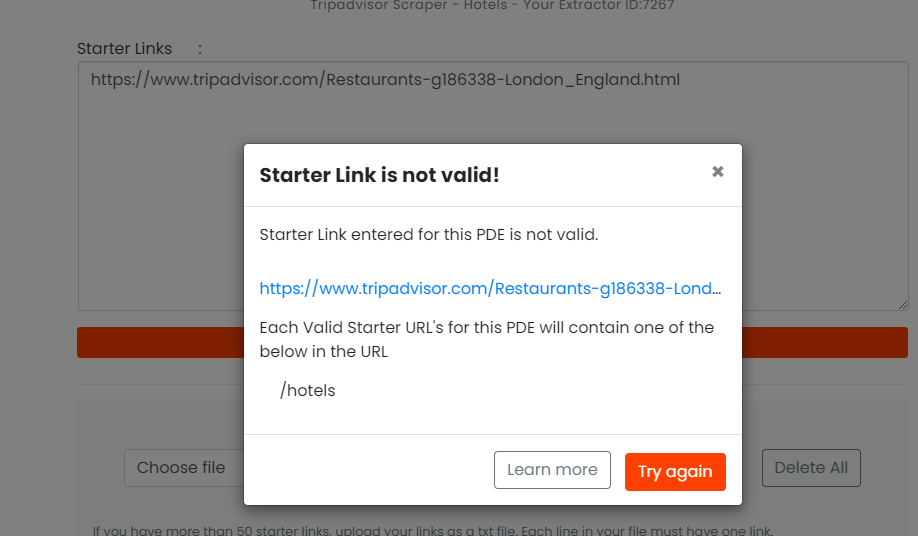
We noticed some customers entering invalid starter URLs to their extractors. When this happens, the extractor fails and causes frustration for users.
Our new feature solves this problem.
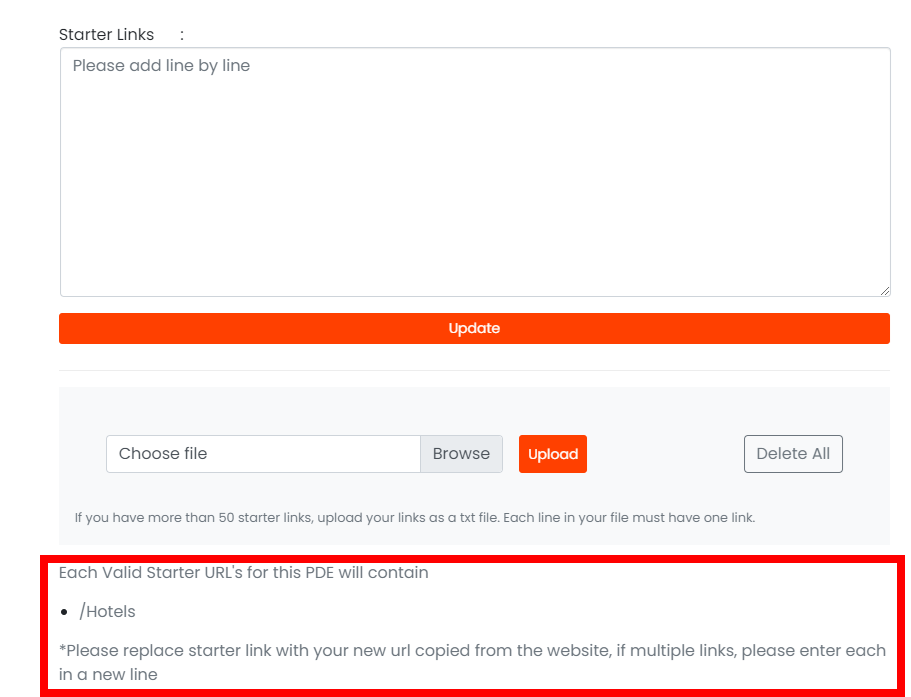
We are creating Starter URL rules for our Pre-Defined Extractors. These rules check whether the entered URL is valid. If you enter a URL that is invalid for the extractor, you will see a pop-up error that shows what a correct starter URL looks like.
We have also written out the rules in the starter link input to remind you of what valid links should contain:
Over the month of May and June, we have been seeking feedback from users. Thank you to all those who gave us feedback we have some great ideas about which new features to focus on next.
UI/UX Revamp
The biggest is a complete overhaul of our user interface.
We recognize that it needs to be simplified and streamlined so you get a Pre-Defined Extractor up and running in just a few minutes.
Zapier Integrations
Over the next month, we will be rolling out integrations to WebAutomation via Zapier, starting with Google Sheets integrations.
Please let us know if you require any other Zapier integrations by emailing us at info@webautomation.io.
If you haven't had a chance to do so, it would help us tremendously if you could take a few minutes and leave a brief review about your experience on Capterra.
We appreciate your honest feedback and we know your time is valuable, so to thank you for helping us out, the first 100 users who leave a validated review will earn a €10 gift card.
Get started now!
We aim to make the process of extracting web data quick and efficient so you can focus your resources on what's truly important, using the data to achieve your business goals. In our marketplace, you can choose from hundreds of pre-defined extractors (PDEs) for the world's biggest websites.
These pre-built data extractors turn almost any website into a spreadsheet or API with just a few clicks. The best part? We build and maintain them for you
Here are the new PDEs we launched in June:
RECENT POSTS
RELATED POSTS
CATEGORIES
follow us on



 Linkedin
Linkedin