
By Victor Bolu @June, 18 2025
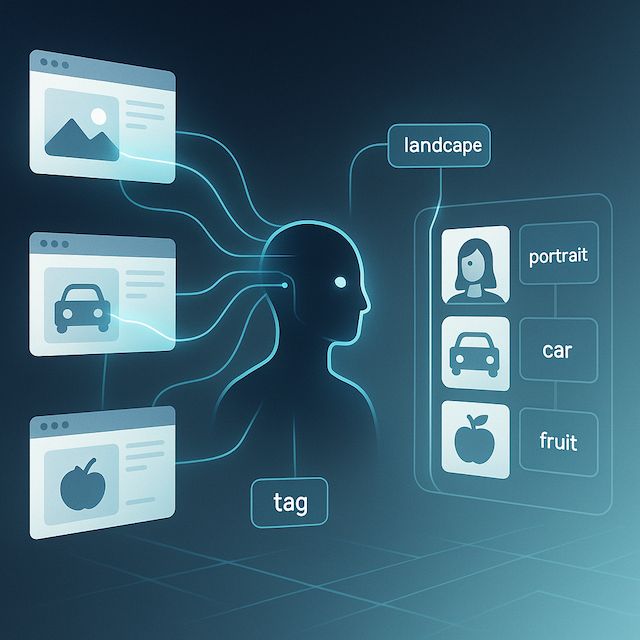
With the advancement of computer vision and machine learning algorithms, creating high-quality image datasets and accurate labelling has become essential for various applications like object recognition, facial recognition, autonomous vehicles, and more. However, manually creating and labelling large datasets can be time-consuming and labor-intensive. In this article, we will explore how web scraping can be used to collect image data and discuss effective strategies for labelling these datasets.
In the field of computer vision, an image dataset refers to a collection of images that are used to train and evaluate machine learning models. These datasets play a crucial role in teaching algorithms to recognize and classify objects within images accurately. Labelling, on the other hand, involves annotating images with relevant information, such as object boundaries, semantic segmentation, or keypoints, to provide ground truth labels for training purposes.
An image dataset typically consists of a large number of images, often categorized into different classes or labels. These images serve as training examples to help algorithms learn patterns and features specific to each class. A well-structured image dataset enables machine learning models to generalize and make accurate predictions on unseen data.
Labelling is a crucial step in creating an image dataset as it provides the necessary ground truth information for training and evaluating models. By assigning labels to images, we enable the algorithm to learn and understand the underlying patterns associated with each class. Accurate labelling enhances the performance and reliability of the trained models.
Creating image datasets can be challenging due to several factors. These include the availability of large-scale, diverse images, time-consuming manual labelling processes, and ensuring high-quality annotations. Additionally, datasets may also need to address biases, privacy concerns, and ethical considerations.
Web scraping is a powerful technique that allows us to automatically extract data from websites. When it comes to collecting image data, web scraping can be a valuable tool for acquiring a large volume of images from various online sources. One such tool that can assist in web scraping is webautomation.io, which provides a user-friendly interface for automating web scraping tasks.
Web scraping involves programmatically accessing web pages, parsing their HTML structure, and extracting relevant information. It enables us to extract not only text data but also images, making it an ideal approach for collecting image datasets. By utilizing web scraping techniques, we can efficiently navigate through websites, locate image elements, and download them in a structured manner.
When it comes to web scraping for image data collection, selecting the right websites is crucial. The choice of websites depends on the specific use case and the type of images you require. For example, in the case of e-commerce products, you might target online marketplaces, such as Amazon or eBay, where you can scrape product images along with their corresponding metadata.
3.3 Scraping Tools and Techniques
To perform web scraping for image data collection, you can utilize various programming languages and libraries, including Python with frameworks like BeautifulSoup or Scrapy. These tools provide functionalities to navigate through web pages, locate image elements using CSS selectors or XPath expressions, and download the images to your local storage.
Tools like webautomation.io can simplify the web scraping process by providing a user-friendly interface with hundreds of pre-built extractors that allows you to automate repetitive tasks without writing extensive code. With webautomation.io, you can interact with web pages, perform actions like clicking buttons or scrolling, and extract image URLs or download images directly.
For e-commerce products, you can use web scraping to extract images, titles, descriptions, and other relevant information from product listings. This data can be used for various purposes, such as building recommendation systems or conducting market research.
In the case of self-driving cars, web scraping can be employed to collect images from traffic camera feeds or dashcam videos. These images can serve as training data for object detection, lane detection, or other computer vision tasks in autonomous driving systems.
By leveraging web scraping techniques and tools like webautomation.io, you can efficiently collect large volumes of images from relevant websites for your specific use case. This automated approach saves time and effort compared to manual downloading, enabling you to create diverse and comprehensive image datasets.
After scraping images, it is crucial to clean and filter the dataset to ensure data quality. This involves removing duplicate or irrelevant images, handling corrupt files, and addressing any inconsistencies in the data. Cleaning the dataset helps to reduce noise and improve the accuracy of the trained models.
To ensure compatibility and ease of use, it is recommended to standardize the format and size of the images in the dataset. Resizing images to a consistent resolution and converting them to a common image format, such as JPEG or PNG, simplifies the subsequent processing steps.
To evaluate the performance of machine learning models, it is common practice to split the dataset into training, validation, and testing sets. The training set is used to train the models, the validation set helps tune hyperparameters, and the testing set evaluates the final model's performance. Proper organization and partitioning of the dataset are crucial for unbiased evaluation.
Image labelling can be performed manually or with the assistance of automated tools. Manual labelling involves humans annotating images using specialized annotation software. Automated labelling utilizes pre-trained models or machine learning algorithms to generate annotations automatically. The choice between manual and automated labelling depends on factors such as dataset size, complexity, and available resources.
There are several annotation tools available that facilitate the labelling process. These tools provide functionalities for drawing bounding boxes, creating polygons, or segmenting objects. Some popular annotation tools include Labelbox, RectLabel, and VGG Image Annotator (VIA). Choosing the right tool depends on the specific labelling requirements and ease of use.
To ensure the quality and consistency of annotations, it is essential to define clear annotation guidelines. These guidelines should cover aspects such as object boundaries, labeling conventions, and handling ambiguous cases. Regularly reviewing and validating annotations can help identify and correct any potential errors or inconsistencies.
Before starting the dataset creation and labelling process, it is important to define clear objectives and requirements. Clearly specifying the classes or labels to be annotated and providing detailed annotation guidelines ensure that the dataset aligns with the intended use case.
Striking the right balance between dataset size and quality is crucial. While larger datasets can improve model performance, it is essential to maintain high-quality annotations. Quality control measures, such as inter-annotator agreement checks and validation processes, can help ensure the reliability of the dataset.
To keep up with evolving models and changing requirements, it is advisable to update and expand the dataset regularly. Adding new images and annotations improves the dataset's diversity and generalization capabilities, enhancing the performance of trained models.
Bias in image datasets can lead to biased model predictions. It is crucial to address and mitigate bias by carefully selecting diverse image sources, ensuring balanced representation, and being mindful of potential ethical concerns. Regular audits and reviews of the dataset can help identify and rectify biases.
Creating an image dataset and labelling it accurately are critical steps in developing robust computer vision models. Web scraping provides a valuable method for data collection, while proper dataset preparation and organization ensure usability and effectiveness. By following best practices, such as defining clear objectives, using appropriate annotation tools, and addressing bias, you can create high-quality image datasets that enable the development of reliable and accurate machine learning models.
The time required to create an image dataset depends on various factors such as dataset size, complexity, available resources, and labelling method. It can range from several days to several months, or even longer for large-scale projects.
Using publicly available images for your dataset is possible, provided you comply with the terms and conditions set by the image source. Always ensure that you have the necessary rights or permissions to use the images for your intended purpose.
Commonly used annotation formats include Pascal VOC, COCO (Common Objects in Context), YOLO (You Only Look Once), and LabelImg XML. These formats specify object annotations, labels, and other relevant information for training machine learning models.
To evaluate the quality of your labelled dataset, you can employ measures such as inter-annotator agreement, where multiple annotators label the same set of images, and their annotations are compared for consistency. Additionally, conducting validation experiments on a held-out dataset can help assess the model's performance.
Experience the Next Level of AI Training with Our Custom Image Dataset Creation Service. We make it easy for you to create an image dataset. Our expert team collaborates seamlessly with you, understanding your specific requirements and objectives. From data collection to annotation, we handle the entire process, ensuring efficiency and accuracy. With customized solutions, we tailor the dataset creation to your needs, incorporating specific categories, labels, and quality standards. Utilizing advanced techniques like web scraping and image filtering, we curate high-quality images. Whether you need a small or large-scale dataset, we offer scalable options. Get started now and revolutionize your AI applications!
RECENT POSTS
RELATED POSTS

How To Grow Your Business With Web Scraping
@13/06/2023
CATEGORIES
follow us on


 Linkedin
Linkedin