
By Victor Bolu @June, 13 2023
HOW TO WEB SCRAPE JAVASCRIPT CONTENT
PREREQUISITES
Basic understanding of
HTML5.
CSS3 Selectors (with Pseudo classes and Pseudo selectors).
Javascript & Node.js
ES6 Javascript syntax (or its progression) - Array and Object Destructuring, REST and Spread Operators, async … await, Promise.
OBJECTIVES
By the end of this article, you will be able to build crawlers that scrape Javascript content.
INTRODUCTION
General Introduction
Web scraping is referred to as the process of getting data from websites (and their databases). It may as well be called Data scraping, data collection, data extraction, data harvesting, data mining, etc. People collect data manually but there is an automated part of making computers do the hard work while you are asleep or away. Anyone could do the manual way, that is why we are focusing on automating the process of web scraping.
It started as writing scripts to visit a website and extract necessary data after parsing the source codes of the HTML or XHTML document returned. Many programming languages have inbuilt modules to load a website by making network requests, and there are APIs for parsing returned documents:
PHP has the curl or PHP-curl extension that can be enabled to allow making HTTP requests with curl, and Simple HTML DOM is a framework for parsing HTML documents.
Python has the request module for making HTTP requests, and BeautifulSoup for parsing the HTML contents.
In node.js, there is the request-promise module for making HTTP requests and cheerio (with the popular jQuery syntax) for parsing HTML documents.
And you could write a bash script to use curl to make HTTP requests and find a way to parse the HTML.
There are several other ways to automate the process of web scraping, or building web crawlers.
The Growth
Over the years, a lot of web developers have upped their development game, they switched lanes from developing websites the traditional way to a very modern way.
Websites used to be written with HTML, CSS, and a few Javascript. But now, a lot has changed and while web developers still write HTML and CSS, Javascript is what writes out over 99% of the document. With front-end frameworks like React.js, Vue.js, Angular.js, and the rest, the most minimal HTML is rendered most of the time, and javascript is required to do the necessary calculations and render the other HTML.
Human users enjoy this change because the new features added have a nice user interface and user experience. Web crawlers on the other hand find this challenging because understanding javascript does not come naturally to them. Not that HTML is easy for them in the first place, they rely on HTML parsers to help them with their assignments.
The simple solution is being able to build web crawlers that understand Javascript or at least have their way around it. If web developers upped their game, web scraping bots developers too must keep up so as not to become old-fashioned.
The technical solution is building web crawlers that are well able to launch a headless browser and drive the browser till the end of the scraping process so that all of the scraping activities happen in the browser. The browser makes the network requests, evaluates the Javascript and updates the DOM (Document Object Model) accordingly, and also provides an interface (very similar to the developers' console) for parsing the HTML documents. This article walks you through it
GETTING STARTED
Selenium web driver, PhantomJS, Playwright, and Puppeteer are popular APIs that developers use to drive a headless browser. But this article is on the Puppeteer and Node.js a language
Make sure Node.js and NPM are installed
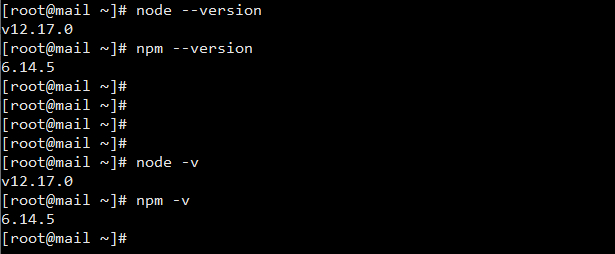
First check if your Node is installed by running node --version (shortcut: node -v) on the terminal (also called shell or command line but for simplicity purposes, let’s stick to terminal throughout this article) and that npm (node package manager) is also installed by running npm --version (shortcut: npm -v). The two should output the current version of Node and npm you are running as shown below:
unless Node is not well installed on your version where you will now have to install it. Make sure you are running Node.js v12 or a later version. It is recommended you are running a stable release.
Create a folder and set it up for your web scraping project
A good practice is to have a folder where all your web scraping projects are stored and you should name each folder the name of the project or rather follow a naming convention for your projects. The first step is to create a folder and navigate to it on the command line (also called terminal or shell). The folder I created for this project is js-dependent-scrape.
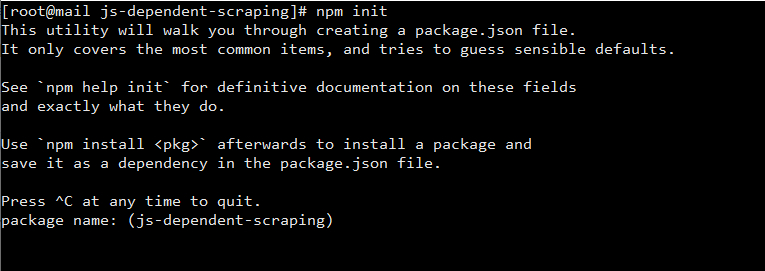
Then run npm init in your project directory and you will have an interactive screen waiting for your inputs like below:
As you can see the package name is having js-dependent-scraping in brackets which is the name of the folder I ran npm init in. if your project name is the same as the folder name just hit the Enter/Return key and your folder name is used as the package name otherwise enter the name you would like to name your project before you hit enter.
Provide the necessary inputs you are asked, noting that the ones in brackets are the default and hitting the Enter key auto-fills in the default. And if there is any you are unsure of just hit the Enter key to continue.
When done, you will be shown a JSON containing your entries and you will be asked if the value is okay with yes in brackets as the default. You can hit Enter if it is okay or type no if otherwise and redo it. You should then have a screen similar to:
You will then have a package.json file created in your directory.
Open your project in an IDE
IDEs come with cool features and add-ons that make writing your codes very easy. Popular IDEs include VS Code, Net Beans, Android Studio, Eclipse, Sublime, etc. But I will be using VS Code in this article. Whatever IDE you use, learn how to use them well and if you do not already have one, download VS Code for your Operating System, install it and start using it.
Create necessary files
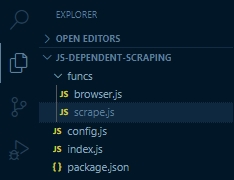
A good practice for developers to follow is having in their project folder:
Such that the project directory looks like this:
Install Puppeteer
Puppeteer is a Node.js library that provides us with an interface to drive a web browser in a way that the browser executes all in-page JS Code, fires necessary JS events, and all the other things a browser does. This in turn makes the server believe it is a real user accessing their resources and allows full access to our script.
Puppeteer is to run Chromium or Firefox in headless and non-headless mode. But developers run in headless mode almost all the time, the only time we run in non-headless mode is when we are debugging or just curious as non-headless makes us have visuals and see what our script is doing. You should always return to headless mode when done.
To install puppeteer, run npm install --save puppeteer (shortcut: npm i -S puppeteer ) from the terminal in your project directory, and allow it to run to the end.
SETTING UP THE PROJECT
We will be creating a function in the funcs/browser.js file, one launches a browser in headless mode and opens new pages. We will then export these functions so that other files can access them.
A simple function to launch the browser is:
|
const launchChrome = async () => { let chrome; |
All the above does is launch Chrome, we need to create 2 functions inside this function such that our function returns an array of the 2 functions. The first function creates a new page and the second function exits the launched browser.
It is better to use the async/await syntax (like you see above) when the next statement or expressions or functions depends on the current one.
The newPage function:
|
const newPage = async () => { |
And the exitChrome function:
|
const exitChrome = async () => { |
So, the funcs/browser.js file looks like:
|
const launchChrome = async () => { let chrome; |
Always use try … catch in blocks that are likely to throw errors, most especially in a Promise or an async block. So that you can catch the errors as they get thrown. Not doing so would stop the execution of the script when the errors are thrown. And the thing about building a Javascript-dependent crawler in Puppeteer is that you might meet a lot of surprises and uncertainties.
In the future, not using try … catch will be deprecated in Javascript.
HAVE A SOLID PLAN
It is a good practice to write down your thought process before building a web crawler. It is simply having an algorithm or a flow of how the project will work.
For instance, if you want to build a web crawler that scrapes people's data from a website. You will want to have the flow like:
Launch Chrome and open a new tab
Visit the homepage of the target website
Click on the category
Extract the data of the people listed on the web page
Save the data
Above is a simple flow of how a web crawler scrapes data from a website. It is good to know your target website very well before getting an algorithm for scraping. You should keep in mind that depending on the target website flow might get complex but having a better flow makes you add necessary intelligence to the web crawler.
Knowing your target website gives you a reliable and unstoppable way of scraping them effectively.
HOW TO SCRAPE USING THE ABOVE FLOW
Launching Chrome and opening a new page
First, we will be importing launchChrome from funcs/browser.js into funcs/scrape.js and then use them to ease things up. funcs/scrape.js would look like:
|
const scrapePersons = async () => { |
This is a really good interface to program our web crawler on - to bring to life our thoughts and imaginations.
2. Visiting a URL
Now, we use the page.goto function to visit URLs. It takes two parameters, the first is the URL to visit and the second is an object specifying the options to use in determining when the URL is considered opened. The object has only two options:
timeout - the maximum number of time (in milliseconds) to wait for the navigation. 0 disables timeout. The default is 30000 (30 seconds) but can be changed by the page.setDefaultTimeout and page.setDefaultNavigationTimeout methods.
waitUntil - determines when the request has been processed and the Promise resolves. It must be any of load (which resolves when the load event has been fired), domcontentloaded (when domcontentloaded event has been fired), networkidle2 (when there are 2 less running network connections for at least 0.5 seconds), and networkidle0 (when there are no more running connections for at least 0.5seconds). The default is load.
page.goto returns a Promise that gets rejected when the navigation to the URL is considered successful depending on the waitUntil option passed.
Increase the timeout option when you are on a slow network connection or if you have launched Chrome with proxy and you are not sure of how fast the proxy server responds. Be well aware that it might slow down the web crawler, you would however make better crawlers.
We will be using only the waitUntil option and we will be setting it to networkidle0 so as to make sure the page.goto function resolves when all the network connections have been settled. We will not be using the timeout option right now.
So, our funcs/scrape.js file looks like:
|
const scrapePersons = async () => {
await exitChrome(); // close chrome |
3. Clicking an element in Puppeteer
The first thing when clicking a button is to know the CSS/JS selector of the button and then click the button by its selector.
Knowing the selector of an element
To know the selector of an element, you should open the particular page where the element is in your own browser.
I assume you use a modern browser like Google Chrome, Firefox and the likes, if not please find out how to access the developer tools in your browser and how to inspect an HTML element in your browser.
So, right-click on the element and click on Inspect, this opens developer tools and shows you the tag name and attributes of the HTML element, you can then use this to compute the selector of the element.
You might run into some situations where multiple elements are having the same selector where you would have to employ the use pseudo-classes like first-child, last-child, nth-child, first-of-type, last-of-type and nth-of-type and some others to get more specific selectors.
To verify you have gotten a valid selector of the element, use the Console tab of the developer tools to run:
|
document.querySelector("{THE SELECTED YOU CAME UP WITH}"); |
If it returns the HTML element in question, you have gotten a valid selector. And if otherwise, you need to retry this process.
Some nodes can only be selected by the use of pseudo-elements.
Clicking an element by its selector
We will be looking at 3 ways by which we can do this
page.click finds the element’s selector and scrolls it into view if out of view before clicking the element. It returns a Promise that either gets resolved as soon as the element has been clicked or throws an error if the element is not found in the DOM.
It accepts two parameters, the first is the element’s selector and the second is an object that specifies the click options:
button - specifies the mouse button to use in clicking the element. It must be a string value of one of left, right, or middle. left means left click, middle means to click with the middle button and right means right-click. The default is left.
clickCount - specifies the number of times to click the element. It must be a number. 2 means double click, 3 means triple-click. The default is 1.
delay - specifies the time (in milliseconds) to wait between mousedown and mouseup. It must be a number. 2000 means hold the mouse button down for 2 seconds. The default is 0.
Using clickCount: 3 on an input element highlights the value of the input if any value is there such that the highlighted value gets deleted when you start typing into the input field, while on an unclickable element the innerText of the element if any gets highlighted/selected.
|
const clickBtn = async () => { |
Using the page.waitForSelector and then click function
page.waitForSelector waits for an element to appear in the DOM. It returns a Promise that either gets resolved as (a clickable element’s handle) as soon as the element is found in the DOM or rejected if the element is not found.
It accepts two parameters. the first is the element’s selector and the second is an object that specifies the wait options:
timeout - just like the page.goto timeout option. Except that you could change the default with just the page.setDefaultTimeout function and not page.setDefaultNavigationTimeout.
visible - make it wait till the element is visible in the DOM i.e. it does not have any of the CSS display: none or visibility: hidden declaration. It must be boolean (true or false). The default is false.
hidden - make it wait till the element is visible in the DOM i.e. it has either the CSS display: none or visibility: hidden declaration. It must be boolean (true or false). The default is false.
You then click the element when page.waitForSelector resolves. For example:
|
const clickBtn = async () => { |
Unlike page.click that attempts clicking an element right away, page.waitForSelector and then click will click the element right away if it is already in the DOM, and if not, it waits for the element to appear in the DOM for the timeout you set or the default timeout.
With page.evaluate, you can run a function on the page. It is like running a function in the Console.
It returns a Promise that resolves to what the function you passed returns or throws an error if any error occurs while trying to run the function in the page context.
|
const clickBtn = async () => { |
A downside of page.evaluate() is that clicking is sort of restricted to using the left button unlike the two other ways of clicking we examined above is that you cannot double click, right click, and do some other types of clicks. But a good thing about this page.evaluate is you will be sure that the button gets clicked even if a modal is over it. Also, you can use it to easily click the nth type of your selector without using pseudo elements.
|
const clickBtn = async (nth = 0) => { |
It is better to prefer the second method ( page.waitForSelector and then click ) over the others because the element might not be available and this method tries to wait some milliseconds for the element to appear in the DOM before clicking it. Another thing about this method is you can decide if you want to click the element only when it is visible or hidden.
You should use the first method ( page.click ) only when you are sure the element is present on the page with the selector you had specified.
You should use page.evaluate for clicking only when you want to click the nth type of an element without having to use complex pseudo-classes . Or when you are not sure there is an overlay on the element, so page.evaluate always work unless the element is not present in the DOM
You should prefer the first two methods over page.evaluate, because they are more human-like. page.evaluate on the other hand is fast, performant, and more bot-like.
4. Extracting Data from a web page
Now, we can use page.evaluate to extract the data we need.
page.evaluate is just like the browser’s console. You can run Javascript codes inside it and have it return what you need. We will need the most common selector of the elements that have the data we want.
Assuming we have 30 <div> elements with such that each <div> has a class person and contains the photo of a person in an <img> tag with the src attribute linking to the person's photo, name in an <h3> tag, email in an <a> tag with class email, and phone number in an <a> tag with class phone. We can extract their photo, name, email and phone like below:
|
const extractPersons = async () => { const photo = personElem.querySelector("img").src; const name = personElem.querySelector("h3").innerText;
// do anything with persons console.log(persons.length, "persons", persons); |
5. Exiting Chrome
We are now done with the scraping. We simply invoke exitChrome to shut the browser down.
|
exitChrome(); |
We need to exit Chrome or the process will not stop unless it crashes.
6. Saving the data from memory
There are different ways and formats to save the extracted data. But we will be exploring 2 popular options. It is good to create a folder for the extracted data. Let’s create extracted-data in our project directory and we shall be saving the extracted data there. This makes our project more structured and organized
Saving to JSON files
We will be using the inbuilt fs module of Node.js to write to files. And we need to use the JSON.stringify function to convert our Javascript objects into a JSON string. We then write the JSON string to our (.json) file
|
const saveAsJson = (data) => { |
Saving to CSV files
CSV is a nice format to present extracted data to users because the files can be opened with Spreadsheet viewing and/or editing software like Microsoft Excel, Google Spreadsheet and the likes. Unlike JSON which is more friendly to developers than to common users.
There are various Javascript modules to use in writing to JSON files. Anyone could come up with a new one at any time and host it on NPM. But we will be using the objects-to-csv module to do this. This module makes writing Javascript objects to CSV a lot easier:
|
const saveAsCsv = async (data) => { |
The objects-to-csv module needs to be installed. You can install it by running npm install --save objects-to-csv on the terminal.
You should invoke the saveAsJson and/or saveAsCsv function after extracting the data.
FINISHING UP
We edit our index.js file so that it runs the scrapePersons function after importing it from funcs/scrape.js. Then, our index.js file looks like:
|
const scrapePersons = require("./funcs/scrape"); |
We then edit the "script" section of our package.json file to have "start" point to index.js . Remove "test" unless you have set up tests for this project. package.json should look like:
|
"scripts": { |
RUNNING THE SCRAPER
Running the scraper is as easy as navigating to your project directory from the terminal and running npm start . npm start runs node index . - the command we specify in the script section of package.json
You could as well run node index directly in a terminal/console.
CONCLUSION
You can always refer to this scraping guide when having any difficulties in a scraping process. If things get too complicated, you can run the browser with headless: false to ease things up because you will be able to see what is going on and debugging will be easier. Be prepared to use proxies to hide your public IP, rotating proxies will be needed if the target website bans IP Address. You will soon be able to approach any kind of web scraping the modern and smart way
Also check out Puppeteer's GitHub repositories, it contains a link to the API Documentation that you should get familiar with to be able to build better and smart web crawlers.
At WebAutomation, We make the process of extracting web data quick and efficient so you can focus your resources on what’s truly important, using the data to achieve your business goals. In our marketplace, you can choose from hundreds of pre-built extractors for the world’s biggest websites.
These pre-built data extractors turn almost any website into a spreadsheet or API with just a few clicks. The best part? We build and maintain them for you!
Using WebAutomation lowers costs, requires no programming, enables you to get started quickly since we build the extractors for you, and means you’ll always have the help you need to keep your extractor running since we handle all the backend security and maintenance.
Web Scraping has never been this easy.






 Linkedin
Linkedin