
By Victor Bolu @February, 7 2023

In today’s world where most of us depend on buying products online, it takes a lot of manual effort to find out on which website the price tag is lowest. So what most of us do is go to one of the most popular websites like Amazon or eBay and buy those products. What if we could easily develop a price comparison tool that can compare the prices from different websites and can then show any user the optimal prices and associated information about that product from different websites in a single place. That is what we are going to do in today’s project.
In this tutorial, we will focus on the below to achieve our goal
Fetching price data from three different websites
Processing data including cleaning it for our purpose
Comparing prices
Storing Data
Visualizing Prices
Program to send Notifications about price change
Using webautomation.io for speeding up Scraping
Web Scraping is a process of collecting relevant information from a particular webpage and then exporting that information in a proper format according to our needs.
Python package for web scraping: Beautiful Soup is a python library that helps in extracting data out of markup languages like HTML and XML.
Other python packages involved: requests
Note: We recommend using google colab / jupyter notebook as an editor for this project, although it is not mandatory.
Step 1: Install prerequisites :
Install Python (https://www.python.org/downloads/)
Install requests (
pip install requests
Step 2: Import packages :
import requests
from bs4 import BeautifulSoup #For web scraping
Step 3: Go to the product page of different websites and get the URL :
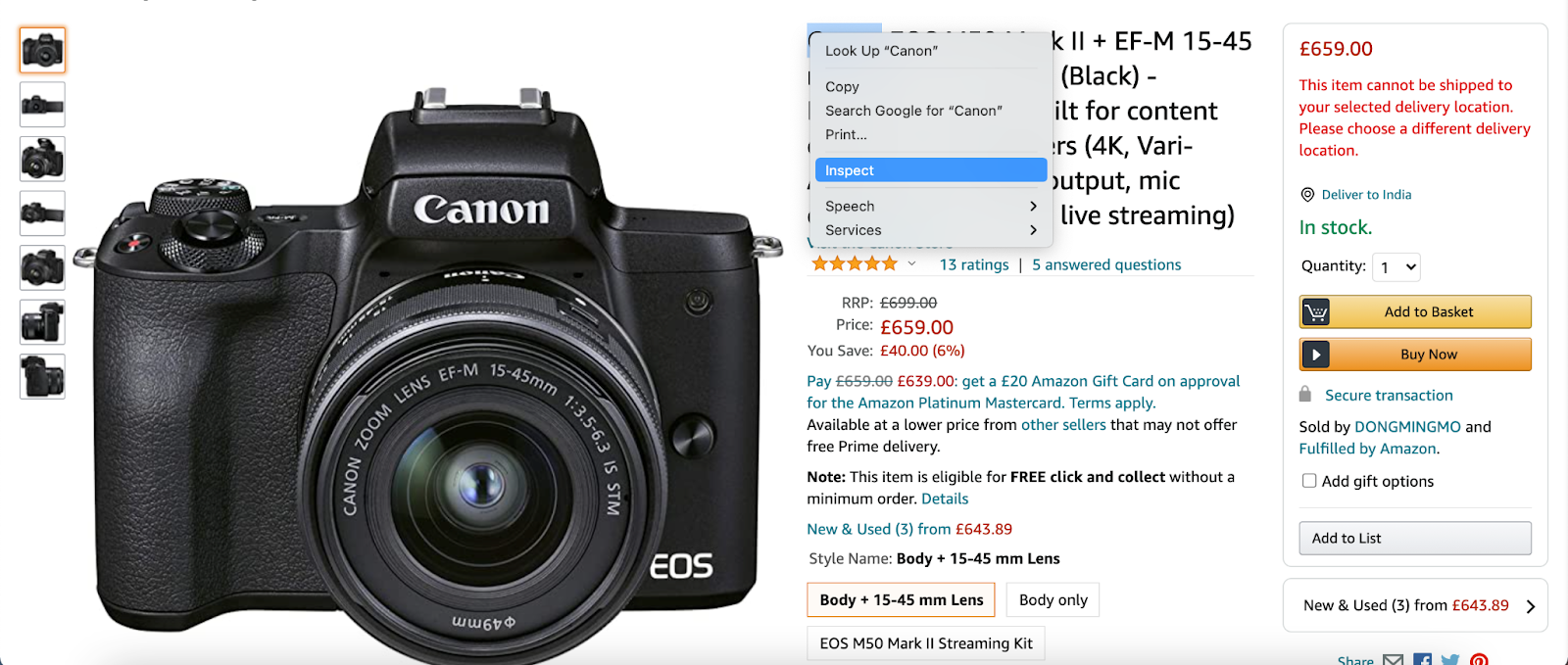
amazon_product_url = "https://www.amazon.co.uk/dp/B08XMPGL7Q/?tag=pr-electronics-21&creative=22374&creativeASIN=B08XMPGL7Q&linkCode=df0"
|
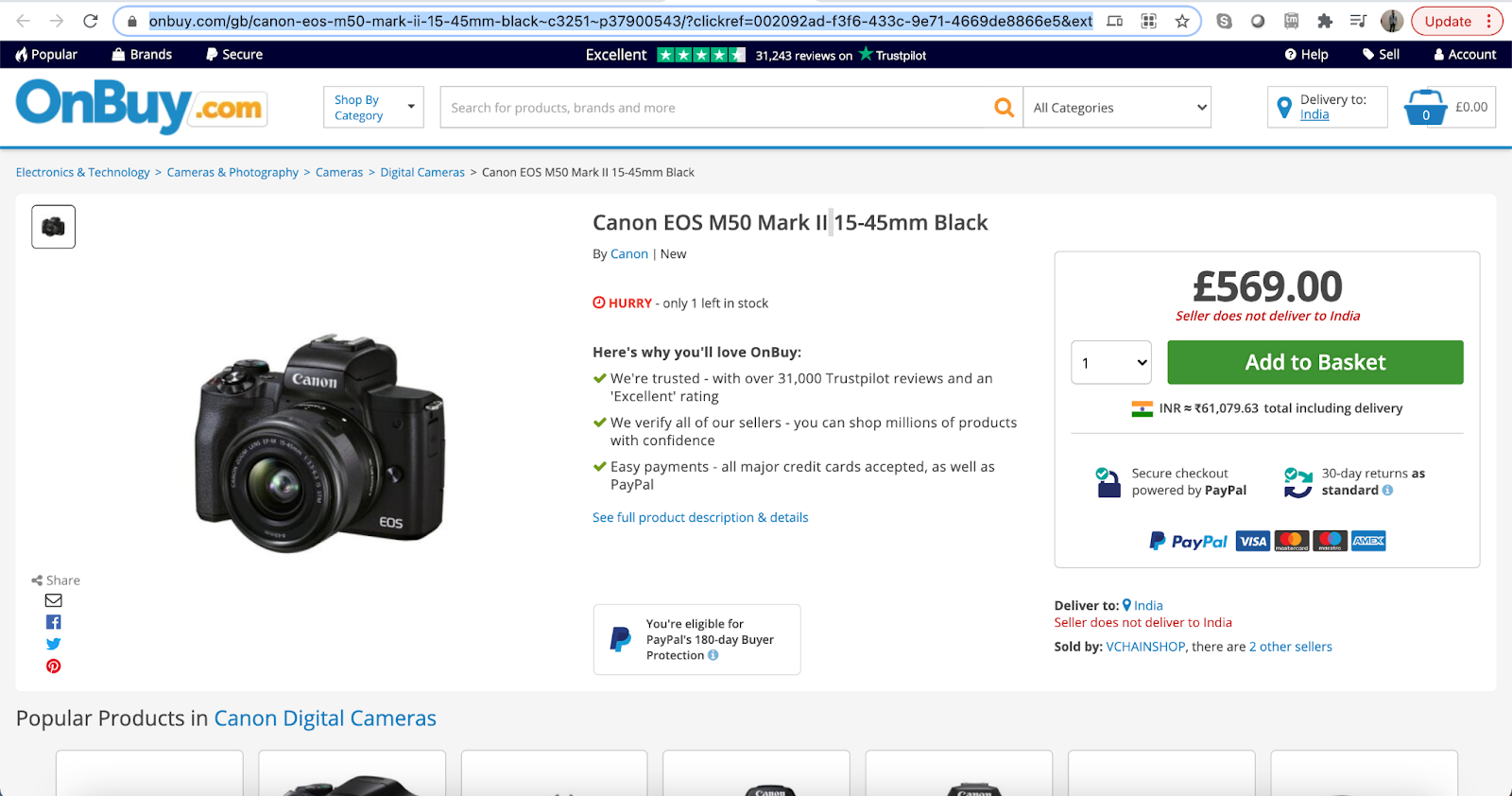
onbuy_product_url='''https://www.onbuy.com/gb/canon-eos-m50-mark-ii-15-45mm-black~c3251~p37900543/?clickref=dd882a92-202e-4a29-81ae-bfc1f53e8d81&exta=prirun&stat=eyJpcCI6IjU2OS4wMCIsImRwIjowLCJsaWQiOiI1MDc4MTk4NyIsInMiOiIxIiwidCI6MTYyMjI0NDE4NCwiYm1jIjowfQ=='''
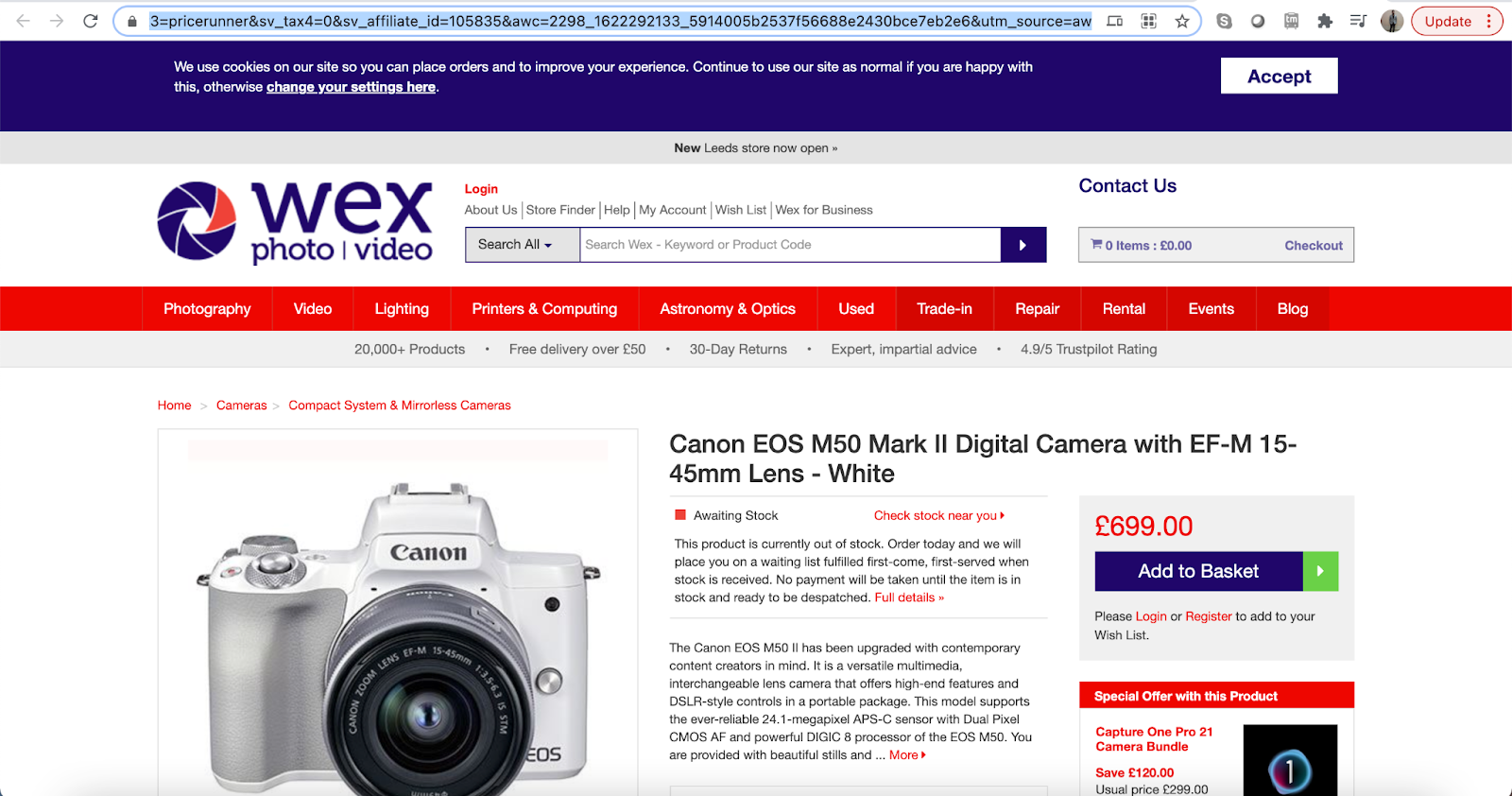
wexphotovideo_url="https://www.wexphotovideo.com/canon-eos-m50-mark-ii-digital-camera-with-ef-m-15-45mm-lens-white-1769301/?sv_campaign_id=105835&sv_tax1=affiliate&sv_tax3=pricerunner&sv_tax4=0&sv_affiliate_id=105835&awc=2298_1622292133_5914005b2537f56688e2430bce7eb2e6&utm_source=aw"''
Step 4: Populate headers :
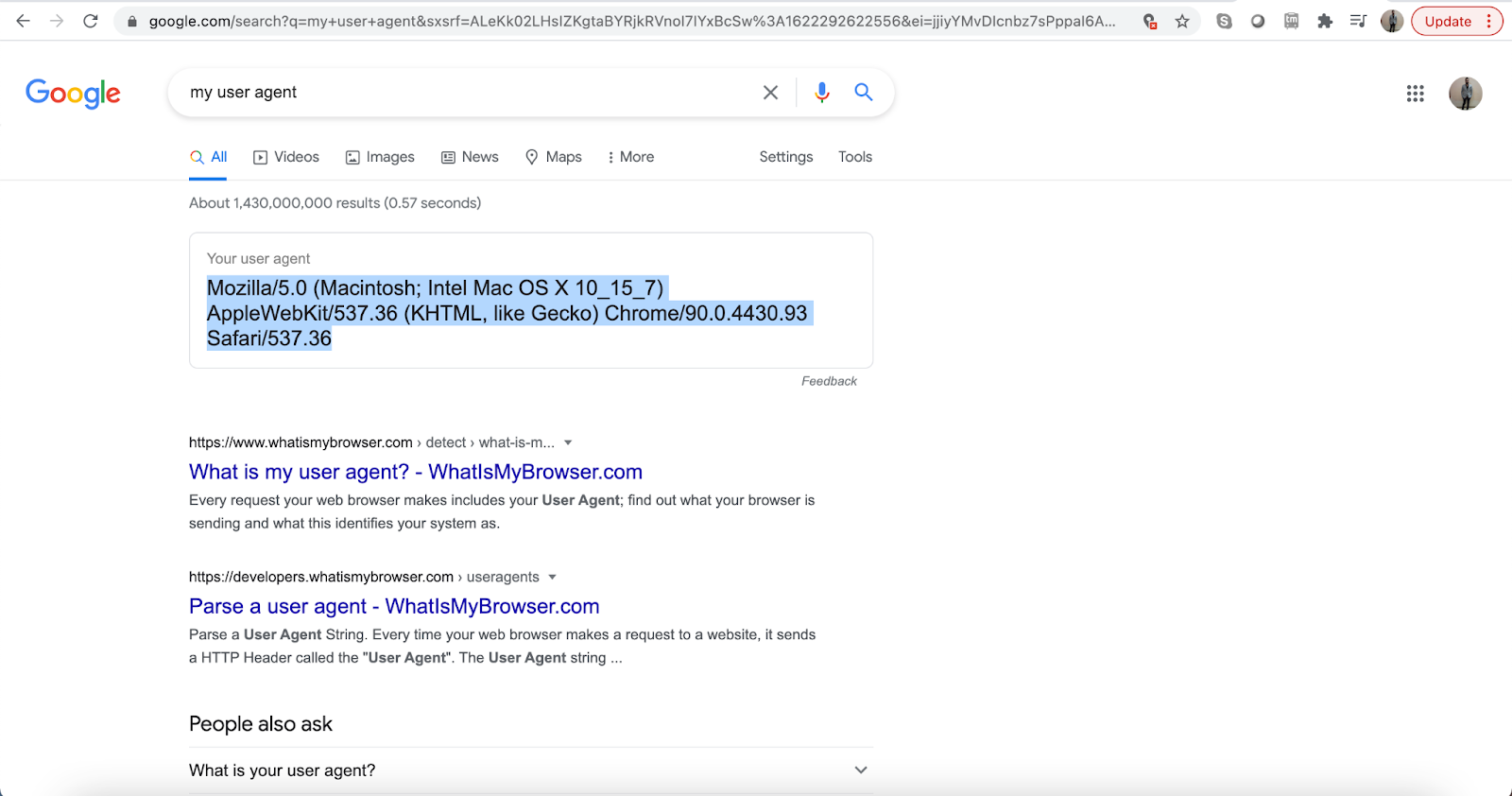
headers = {"user-agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36"}
To get user agent, google my user agent,
For Amazon
page = requests.get(url=amazon_product_url, headers=headers)
soup = BeautifulSoup(page.content,'lxml')
print(soup.prettify())
Now go to the Amazon page, right-click on the product title, and inspect,
You will get the following screen after clicking on inspect
As you can see in the HTML source code, the element with id productTitle contains the title of the product,
title = soup.find(id = 'productTitle')

This will get us the product title but the data should be cleaned to process further, As we can see the data has HTML tags.
To remove tags,
text = title.get_text() # Will get text from html tags product_title = text.strip() # Removing special characters like \n (newline) print(product_title )
We got the product title, which is stored in the variable product_title
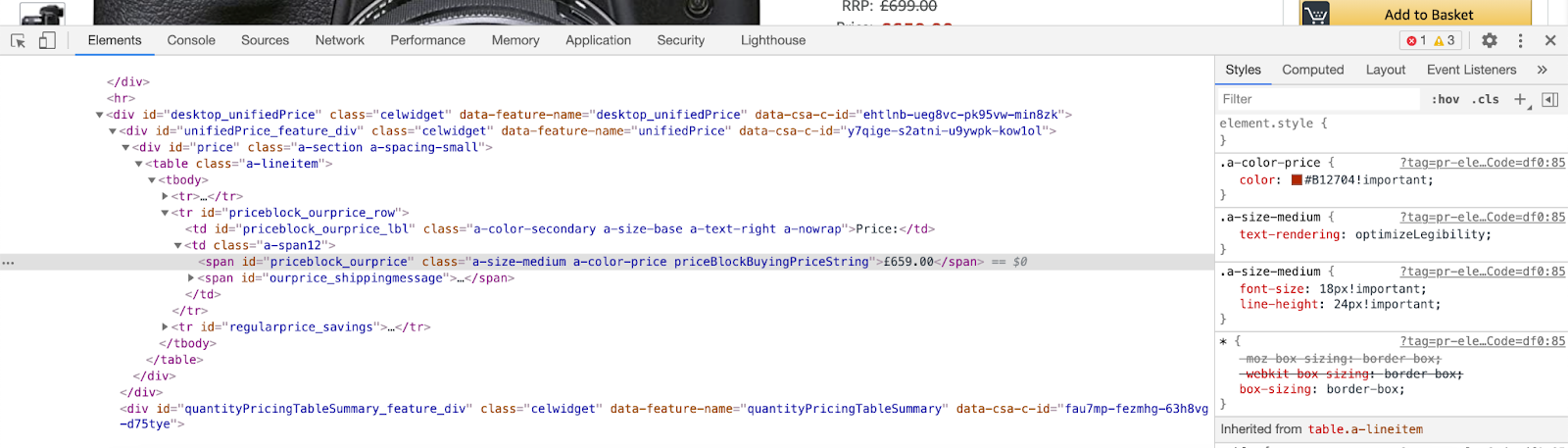
Similarly when we click on the price tag and do inspect we get the following HTML source code,
Here, id priceblock_ourprice contains the price tag. So to fetch the price we need the following code,
price = soup.find(id = 'priceblock_ourprice') price = price.get_text() # Will get text from html tags amazon_product_price = price.strip() # Removing special characters like \n (newline) print(amazon_product_price )
Now we have the product price from amazon in variable amazon_product_price
In the same manner, we will get the price tags from the other two eCommerce websites as well.
For Onbuy
page = requests.get(url=onbuy_product_url, headers=headers)
soup = BeautifulSoup(page.content,'lxml')
print(soup.prettify())
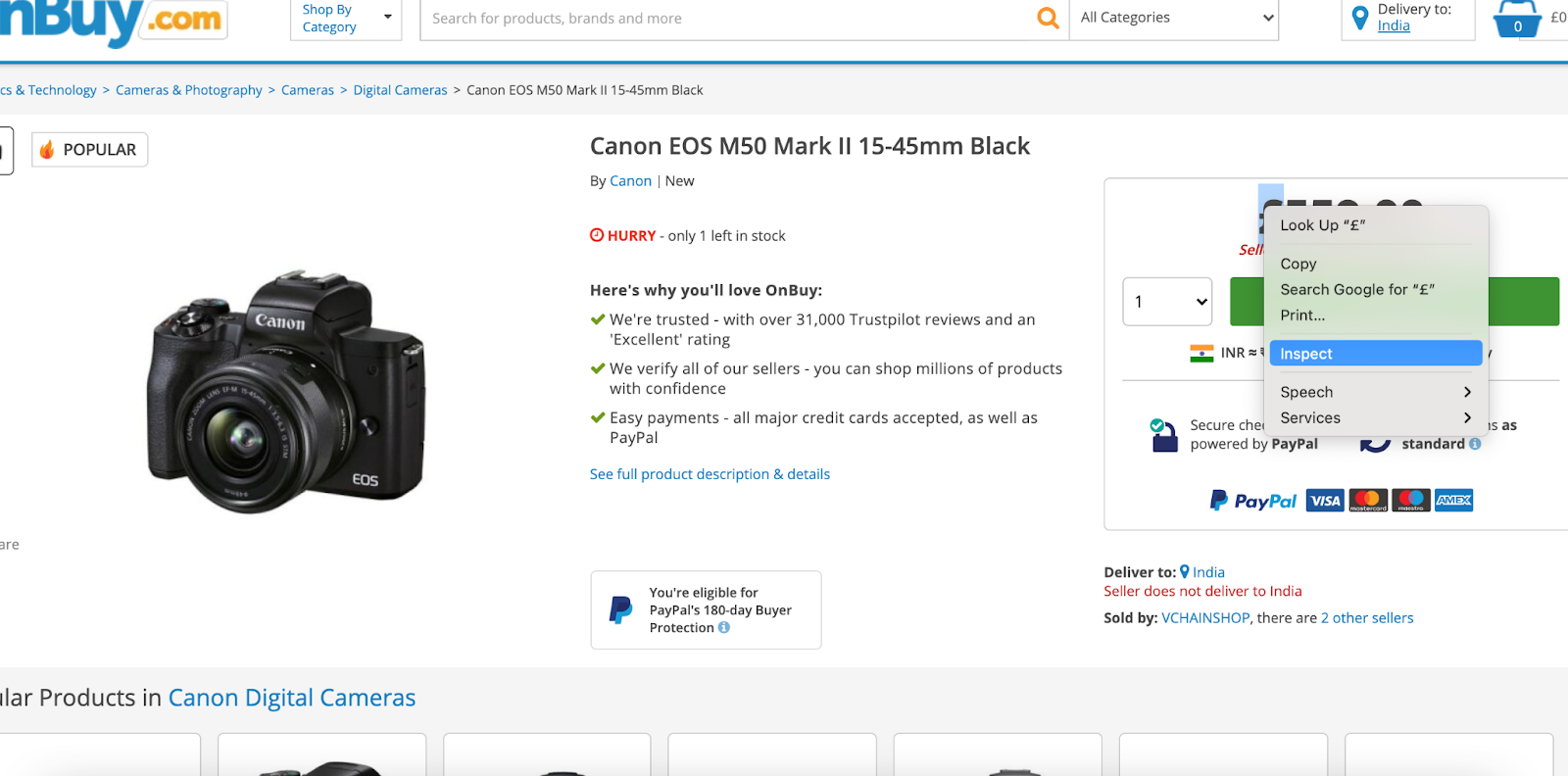
Visit onbuy page, right-click on the product price, and inspect ,
We get the following HTML elements from inspect,
As you can see this layout is a little bit different. Here we will have to fetch the price tag from a class element as opposed to span in Amazon’s case.
So to fetch data from class element in HTML,
For Wexphotovideo :
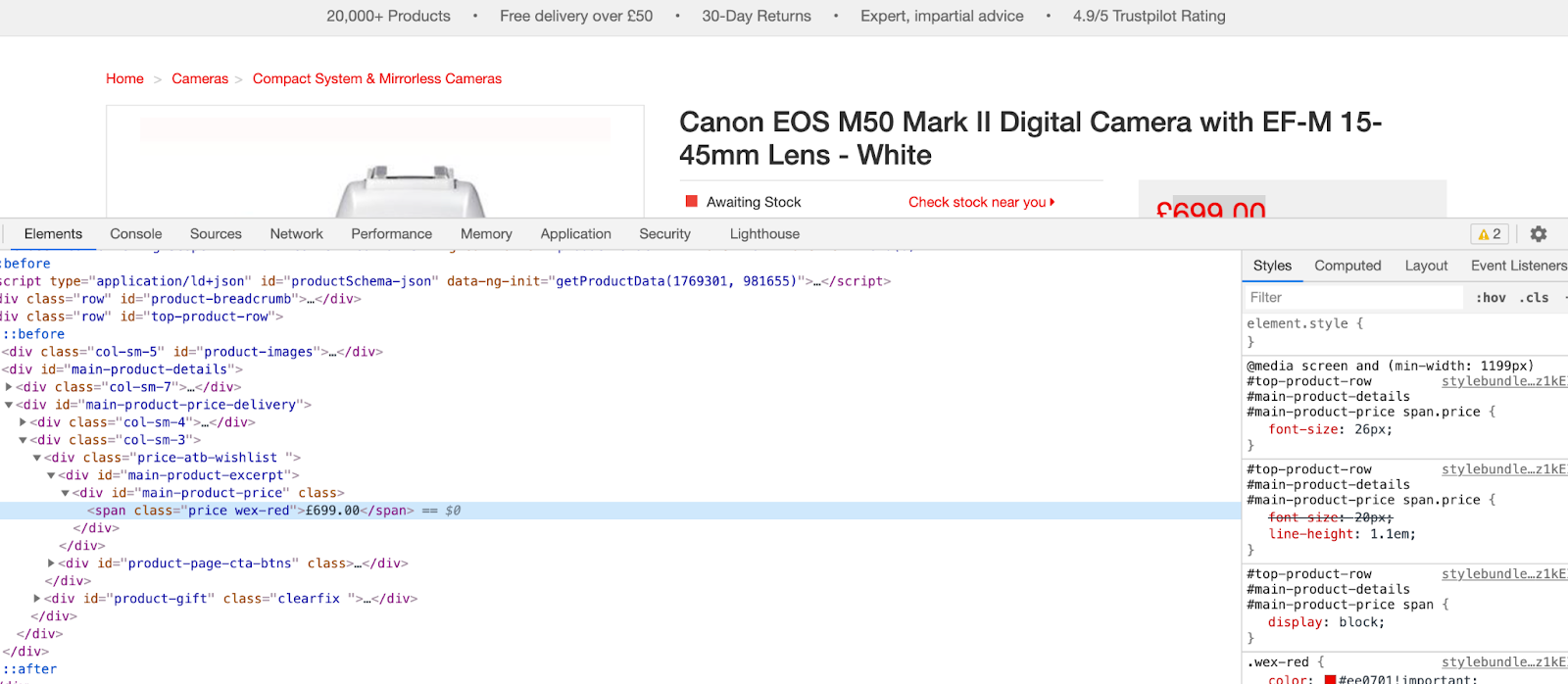
Wexphotovideo has the same layout as onbuy. So we can repeat the same process here,
inspect,
Get HTML data,
Clean and extract price from HTML tags,
tag = soup.find('span', class_ = 'price') # get price element text = tag.get_text() # Removing html tags wex_product_price = text.strip() # Cleaning Data wex_product_price
import pickle def storeData(): # initializing data to be stored in db amazon = {'key' : 'amazon', 'product_name' : 'Canon EOS M50', 'price' : amazon_product_price} onbuy = {'key' : 'onbuy', 'product_name' : 'Canon EOS M50', 'price' : onbuy_product_price} wex = {'key' : 'wex', 'product_name' : 'Canon EOS M50', 'price' : wex_product_price} # database db = {} db['amazon'] = amazon db['onbuy'] = onbuy db['wex'] = wex # Its important to use binary mode dbfile = open('price_data', 'ab') # source, destination pickle.dump(db, dbfile) dbfile.close()
#Loading Stored Data def read_data(): dbfile = open('price_data', 'rb') sb_store = pickle.load(dbfile) for items in db_store: print(items, ' :: ', db[items]) dbfile.close()
Removing currency symbols and converting prices from string to float for comparison.
amazon_product_price = float(amazon_product_price[1:]) onbuy_product_price = float(onbuy_product_price[1:]) wex_product_price = float(wex_product_price[1:])
Finding minimum,
min_price = min (amazon_product_price,onbuy_price,wex_product_price)
if min_price = amazon_product_price, Company = Amazon URL = amazon_product_url else if min_price = onbuy_product_price, Company = Onbuy URL = onbuy_product_url else if min_price = wex_product_price, Company = wex URL = wexphotovideo_url
Company and URL contain the website name and URL for the product which has the minimum price.
We can write a function to send the notification to our mail IDs using SMTP.
Check out our ready-made Airbnb scraper for your price comparison website.Now when we have the prices of data, it is easier to use a bar chart to compare the prices instead of looking at the numbers. Visualization becomes more useful as the number of data points increases.
We have shown here how easy it is to visualize price data from three different websites using a python library called matplotlib. We are using matplotlib bar chart to Visualize the different prices here.

How good can it be to get a notification about any price change that interests you? We have shown in the following code how one can write a simple python script to get notifications via email.
The script here sends a notification about the company with the lowest price with a link that can be used to buy the product. Variable body in the code can be changed according to our needs.
def notifications(): server = smtplib.SMTP("smtp.gmail.com",587) server.ehlo() server.starttls() server.ehlo() server.login("username","password") subject = "Prices Fell Down" body = "Please check {company} , click her {url}".formay(company = Company, url = URL) msg = f"Subject:{subject}, \n\n{body}" server.sendmail("receivermailid",msg) print("mail send") server.quit()
We can schedule this above code to run periodically and send us notifications whenever the price falls.
Alternatively, if you just want a plug-and-play solution where you can just enter the URL and you get the data without even writing a line of code, WebAutomation is just the tool for you.
Try an easy-to-use, pre-built scraper from https://webautomation.io . All you have to do is enter the starting URL of web pages you want to scrap and it will give you the data you want in a nice and clean format that is downloadable.
Steps To Follow:
1 . Sign up for a free trial here https://webautomation.io/account/sgn/
2. You can use a readymade scraper for popular websites like amazon for free at https://webautomation.io/pde/amazon-department-product-scraper/80/
3. You can scrape any link with the help of raw data extractor. This extractor will help you to extract all HTML sources of visited links.
https://webautomation.io/api/redoc/#operation/Scrape .
4. You can also use the API to get structured data https://webautomation.io/api/redoc/
We aim to make the process of extracting web data quick and efficient so you can focus your resources on what's truly important, using the data to achieve your business goals. In our marketplace, you can choose from hundreds of pre-defined extractors (PDEs) for the world's biggest websites. These pre-built data extractors turn almost any website into a spreadsheet or API with just a few clicks. The best part? We build and maintain them for you so the data is always in a structured form. .
How to use web scraping for your price comparison website
Webinar: How to start a price comparison site using web scraping
RECENT POSTS
RELATED POSTS
CATEGORIES
follow us on










 Linkedin
Linkedin