

Our pre-built Reddit Scraper extracts all the comments, posts, usernames and votes from search results of keywords made on Reddit.com
Use for freeOur pre-built Reddit Scraper extracts all the comments, posts, usernames and votes from search results of keywords made on Reddit.com
Our prebuilt reddit.com web scraper lets you extract data including reviews, comments and posts, quickly and easily, from posts made on reddit.com without having to write any code.
Blogs and forums are a great source of alternate data. Given how diverse and easily accessible blogs are, they are a great source of information, not only for the people reading them but for the person scraping them as well.
Blogs like reddit.com can help you understand customer sentiment and consumer preferences.
Active conversations on active blog posts can help you understand upcoming market trends and with enough data, you can even predict the market sentiment towards various topics.
With the amount of being generated on reddit.com every day, it's impossible to go through each of them manually. The data is rapidly changing and always evolving. You need a way to keep up with that change.
And that’s where our predefined web scrapers come into play.
These web scrapers have been designed specially to extract data from the reddit.com. Our simple yet powerful tool automates the whole process of extracting data, without having to write any code.
And the best part? Our reddit.com web scraper is completely free to try!
A few mouse clicks and copy/paste is all that it takes!
* to use you will need to sign up for a FREE TRIAL account
Steps to use:
Step 1: Click on "use for Free"
Step 2: Activate the Pre-Defined extractor by clicking the "Activate button"
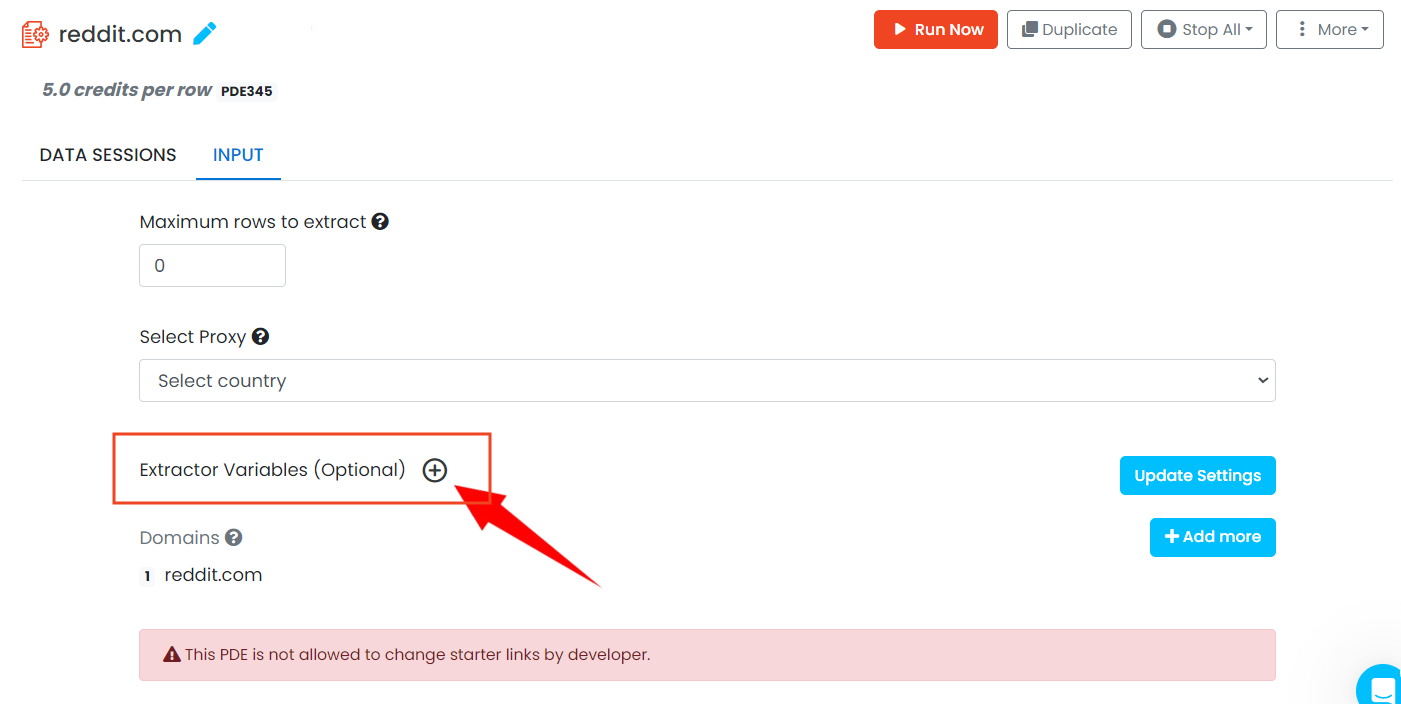
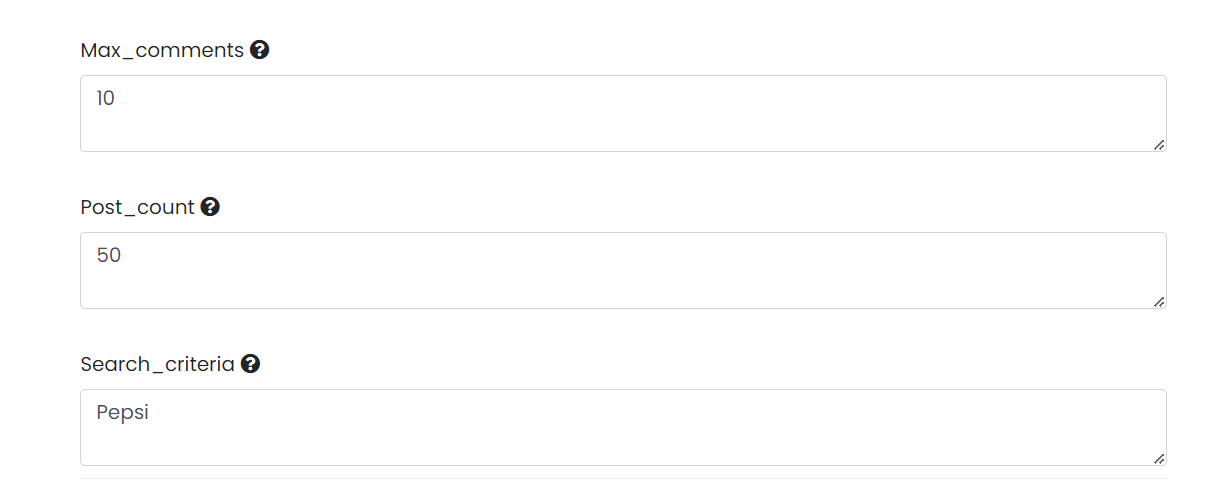
Step 3: Click on the "input" tab and enter a search criteria you would like to scrape from Extractor Variables by clicking the plus button. You can also choose the maximum number of comments and post counts you'd like to scrape from here.
Step 4: Click "Run now"
When you use Reddit Search Results Extractor pre-defined web scraper, the cost will be 5 credits per row which equals to $1 for 200 rows.
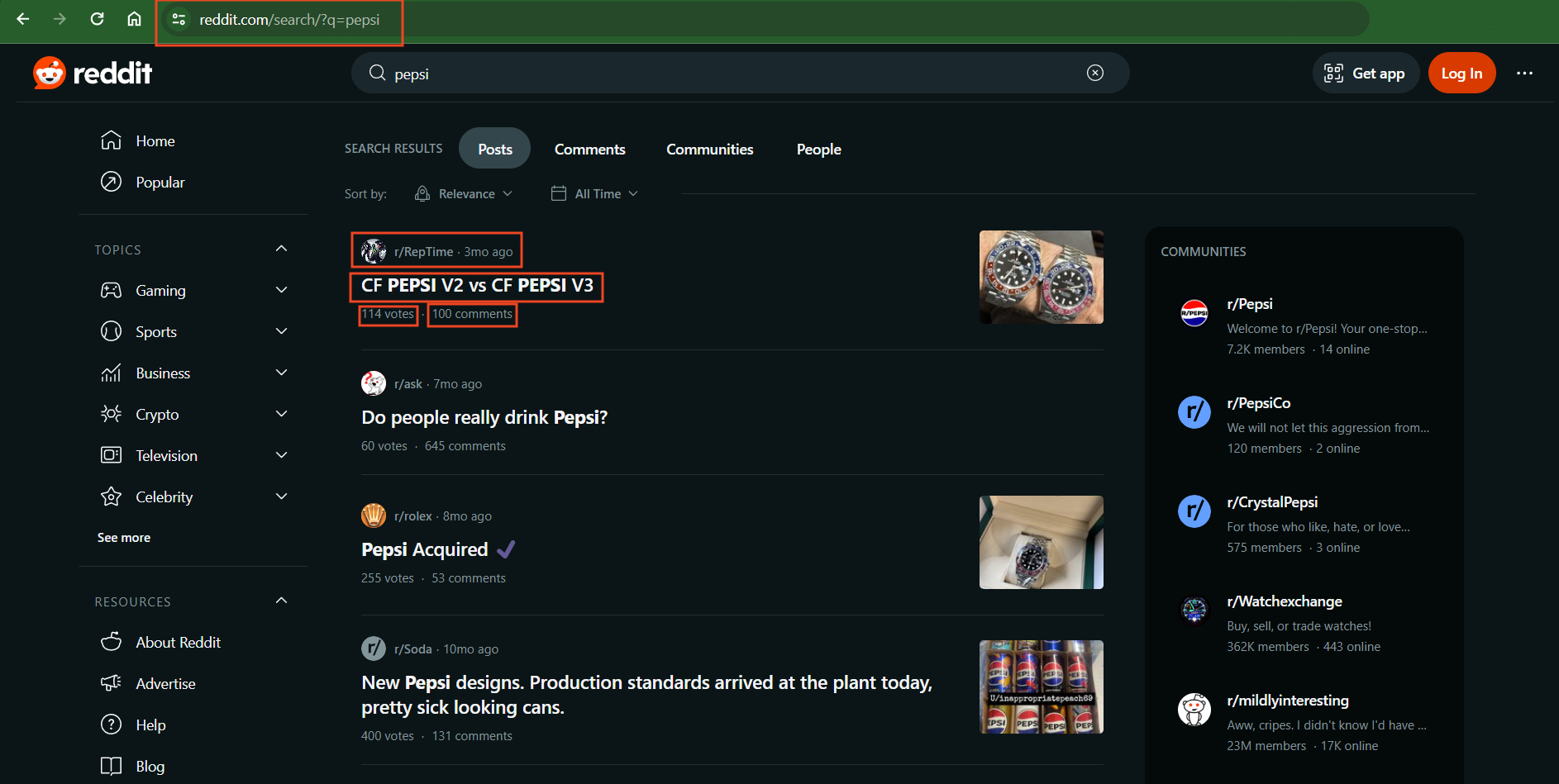
Below is a screenshot of what data fields we will be web scraping from Reddit.com
You will get your data in following structure in different formats:
{
"post_id":"t3_18ja20h",
"Link":"https://www.reddit.com/r/Damnthatsinteresting/comments/18ja20h/pepsi_vs_coke_ants_preference/",
"Domain":"v.redd.it",
"Author":"android_pancake",
"Author_id":"t2_3xauh2cy",
"Number_of_comments":2144,
"Title":"Pepsi vs coke, ants preference ",
"Date":{"year":"2023","month":"12","day":"15","hour":"21:56"},
"Votes":58302,"Source":{},
"Subreddit":"Damnthatsinteresting",
"Text":"Video",
"Comments":[{
"Author":"International-Dig864",
"Author_Id":"t2_al7cdcbk",
"comment_id":"t1_kdixs6r",
"comment_text":"Now repeat the experiment"
}
*** Data below was extracted on Dec 15, 2024 @08:45
To be able to use reddit search results scraper, your account must have the requirements below. If you satisfy the conditions the data output of your scraper will be one click away.
Any question? We'll help you out
Ask about webautomation products, pricing, implementation, or anything else. Our knowledgeable reps are standing by, ready to help.













